Real-time LLM Inference on Standard GPUs: 3k tokens/s per request
blog.kog.ai原文 ↗
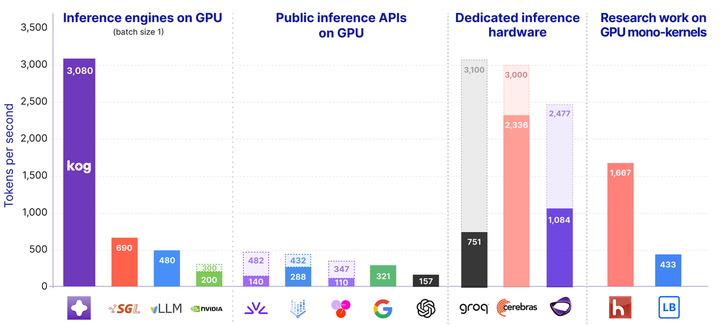
这篇文章的技术看点是把低延迟解码推到 kernel 调度层:减少 kernel launch 和框架开销,尽量让生成过程常驻 GPU。需要谨慎比较的是模型大小、batch、量化、speculative decoding 与硬件配置,否则 tokens/s 数字不可横向复用。
–浏览
评论 · Comments