Harness-1: Reinforcement Learning for Search Agents with State-Externalizing Harnesses
arxiv.org原文 ↗
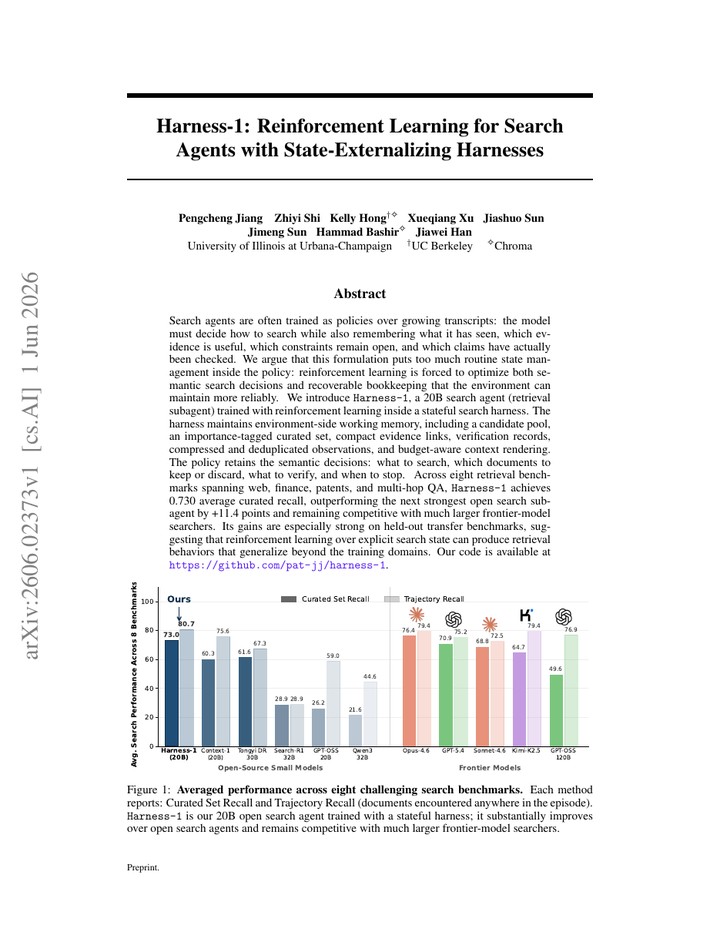
Harness-1 把搜索 agent 的证据、约束、候选答案和检查状态外置到 harness,而不是要求模型在越来越长的 transcript 中自行维护所有状态。贡献是把 RL 训练对象从纯对话策略改成模型加外部状态机,使检索、引用和验证步骤能被显式记录、检查和奖励。值得看的是,搜索 agent 的瓶颈常在跨多轮证据管理和自检,而这篇把状态管理变成了可训练接口。
–浏览
评论 · Comments