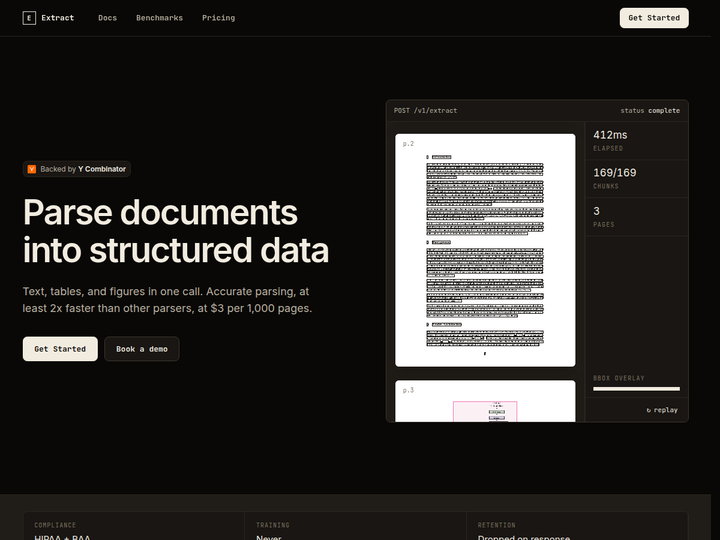
Extract 是 hosted document extraction API,用于把 PDF 等文档抽取为结构化文本、表格、图片和 layout 信息。页面说明它返回 structured spans、bounding boxes 和 font metadata,图片会上传到 object store 并以 image_url 返回;示例 API 支持通过 URL 提交 PDF。它对 RAG 的价值在于保留文档结构,而不只是输出连续纯文本。对于表格密集或版式重要的 PDF,坐标和字体元数据能显著改善后续检索与引用。
–浏览
评论 · Comments