
Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams1 - 把 auto-harness 从固定离线 benchmark 推到开放任务流,并用 harness tree 与 solve-time routing 处理分布漂移。
全文 ↓今日重点 · Today's Highlights
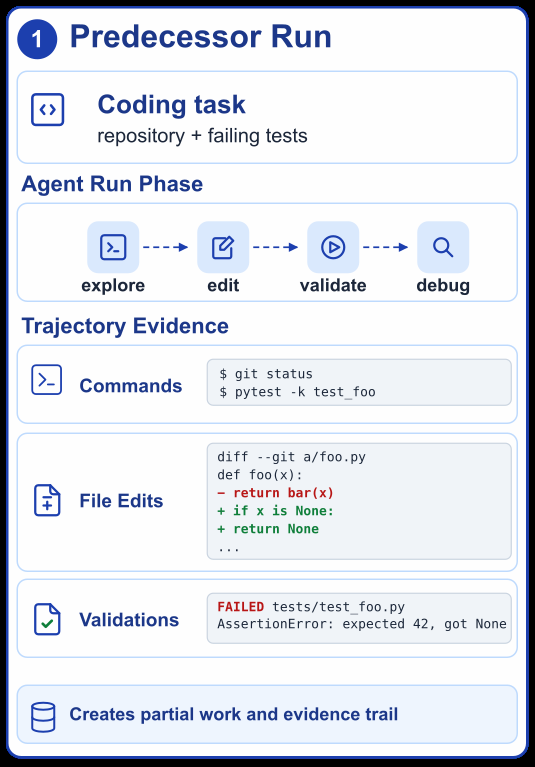
Handoff Debt: The Rediscovery Cost When Coding Agents Take Over Interrupted Tasks2 - 把 coding-agent 交接中的上下文重建成本量化为 events 与 prompt tokens,给协作式 agent 工作流一个可测指标。
全文 ↓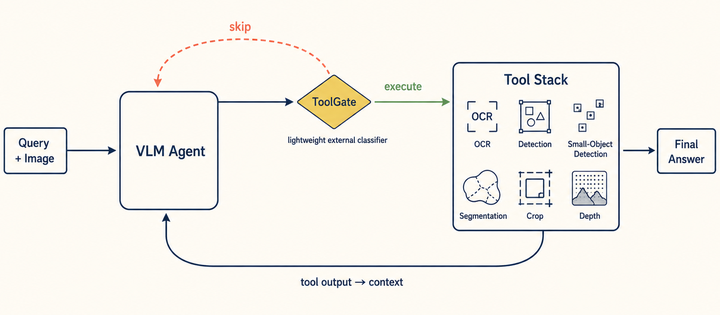
ToolGate: Token-Efficient Pre-Call Control for Tool-Augmented Vision-Language Agents3 - 在 VLM agent 调用 OCR/检测/分割前做 execute/skip 控制,把工具输出成本降到 ReAct baseline 的 64-69%。
全文 ↓
NVIDIA/OpenShell4 - 用 sandbox runtime 与 YAML policy 给 autonomous agents 加文件、网络和凭证访问边界。
全文 ↓
chopratejas/headroom5 - 把工具输出、日志、文件和 RAG chunks 进入模型前压缩,直接作用在 agent token 成本和上下文容量上。
全文 ↓论文 · Papers
15 项 · 论文本期重点Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams1arxiv.org原文 ↗
提出 Adaptive Auto-Harness,用于开放任务流里的 agent harness 持续演化。它把与 oracle harness 的差距拆成 evolution loss 和 adaptation loss,并用 stateful multi-agent evolver、harness tree 的解题时路由,以及人类 steering hooks 来降低两类损失。实验覆盖 prediction-market、security-competition 和 event-forecasting 三类流式任务,报告优于五个 auto-harness baseline。值得看的是它把“自我改进”从固定 benchmark 推到长期、异质、分布漂移的部署场景。
–
本期重点Handoff Debt: The Rediscovery Cost When Coding Agents Take Over Interrupted Tasks2arxiv.org原文 ↗
定义 coding agent 接手中断任务时的 handoff debt:后继者为重新发现前任上下文付出的事件和 token 成本。协议在 75 个源任务上生成 181 个 handoff-point tasks,并对每个 successor model 跑 724 次 takeover;四种视图包括仅仓库状态、raw trace、summary notes 和 structured notes。带上下文的交接相对 repository-only 可把 median agent events 降低 20-59%,prompt tokens 降低 42-63%。这篇把“交接文档质量”转成可测成本,是 coding-agent 生产化里很具体的评估口径。
–

What Benchmarks Don't Measure: The Case for Evaluating Abstention Competence in Autonomous Agents6arxiv.org原文 ↗
主张 autonomous agent 评测不能只看完成率,还要看何时应该停手或拒绝继续行动。论文提出三类 abstention-warranted 场景:specification gap、verification gap 和 authority gap,分别对应信息缺失、世界状态无法确认、授权不足。它的技术价值不在新模型,而在把“拒绝行动”从安全原则变成 benchmark 构造维度。对 agent 评估来说,这能补上很多成功率指标掩盖的越权和臆测问题。
–

Inducing Reasoning Primitives from Agent Traces7arxiv.org原文 ↗
提出 Reasoning Primitive Induction,从成功 ReAct traces 中单遍挖掘、聚类重复推理动作,并转成 typed pseudo-tools。每个 pseudo-tool 由自然语言 docstring 说明,测试时由普通 ReAct loop 组合调用。作者报告 induced libraries 反超生成它们的原 agent:RuleArena NBA 从 30 到 74,MuSR team allocation 从 38 到 68,NatPlan meeting planning 从 7 到 29。它把 scratchpad 里的临时推理经验外化为可复用工具库,机制简单但很有迁移意味。
–
本期重点ToolGate: Token-Efficient Pre-Call Control for Tool-Augmented Vision-Language Agents3arxiv.org原文 ↗
研究 VLM agent 在 OCR、检测、分割等感知工具真正执行前,是否应该跳过该调用。作者发现 baseline 的局部选择性很差,helpful 和 harmful calls 比例接近 11.8% vs 9.9%,多数调用也不会改变 forced-answer prediction。ToolGate 用轨迹文本和结构特征做轻量 execute/skip 控制,在两个 Qwen3-VL backbone 上把 token cost 降到 unrestricted ReAct 的 64-69%,跨域平均准确率仍能保持。它说明感知工具链的效率瓶颈不只是工具本身,还在调用前的控制策略。
–
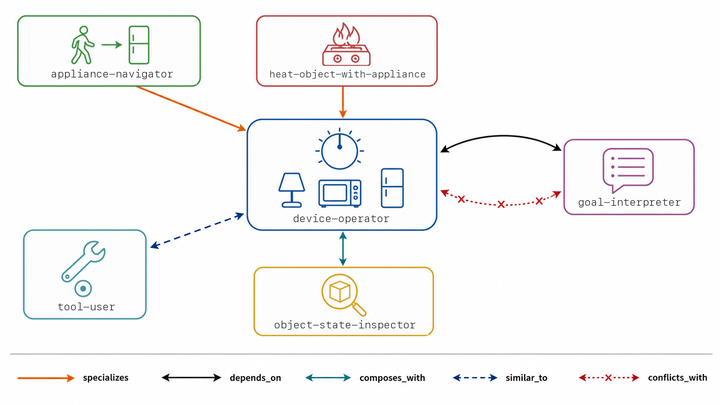
SkillDAG: Self-Evolving Typed Skill Graphs for LLM Skill Selection at Scale8arxiv.org原文 ↗
把大型 skill library 的选择问题建模成 typed directed graph,而不是单纯 embedding 相似度检索。图边表达依赖、冲突、特化和重复关系;每次检索返回 vector matches、typed-edge neighbors 和 conflict signals,agent 还能通过 propose-then-commit 把执行证据写回图。论文在 ALFWorld 和 SkillsBench 上报告 MiniMax-M2.7 达到 67.1% success、27.3% reward,比 Graph-of-Skills baseline 高 12.8 和 8.6 点。它适合关注 skill 数量变大后如何保持选择稳定性的读者。
–

DELTAMEM: Incremental Experience Memory for LLM Agents via Residual Trees9arxiv.org原文 ↗
提出 DeltaMem,用 residual trees 管理 agent 经验,避免把相似 episode 平铺存储导致冗余和检索冲突。系统拆成两棵树:一棵存 goal-conditioned task experience 作为 reusable skills,另一棵存 scene-level environment knowledge;root 表达通用经验,delta node 表达后续差异。检索时沿 root-to-match chain 重构完整经验,并通过 autonomous consolidation 把高频路径沉淀为新 root。它把 agent memory 的重点从“多存”转到“存增量结构”。
–
DeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration10arxiv.org原文 ↗
构建专业桌面 GUI agent benchmark,覆盖设计、视频、音频和 3D 创作等长流程任务,并把人机协作协议纳入评测。DeskCraft 的长任务要求超过 50 个执行步骤,同时建模 mid-turn clarification、用户打断和 post-turn feedback。作者评估 18 个闭源和开源 agent、538 个任务,GPT-5.4 在 standard tasks 上为 31.6%,interactive tasks 为 27.6%。它把桌面 agent 从短指令点击题推进到真实专业软件工作流。
–

InfoMem: Training Long-Context Memory Agents with Answer-Conditioned Information Gain11arxiv.org原文 ↗
提出 InfoMem,用 answer-conditioned information gain 训练 chunk-wise long-context memory agents。核心奖励衡量最终 memory 对 ground-truth answer 每 token log-likelihood 的提升,而不是只看稀疏最终答案或词面重合。论文在相同 GRPO 框架和训练预算下优于可比 RL memory-agent baseline,并指出 reward 应只作用于成功轨迹、先归一化、且条件应是 answer 而非 query。它给长上下文 memory 训练提供了更贴近最终可回答性的中间信号。
–
What Makes Interaction Trajectories Effective for Training Terminal Agents?12arxiv.org原文 ↗
研究 terminal-agent post-training 中,强教师是否必然给出更好的训练轨迹。作者用 Terminal-Lego 把真实 multi-domain issue 转成可环境验证任务,发现 Claude Opus 4.6 虽在 Terminal-Bench 2.0 分数更高,但 DeepSeek-V3.2 轨迹微调出的学生泛化更强。关键解释是 Environment-Grounded Supervision:显式暴露 inspect-act-verify 行为的轨迹更利于学生学习。一个醒目的数字是 15.3k 条 Terminal-Lego trajectories 让 Qwen3-32B 在 Terminal-Bench 2.0 达到 24.3%,接近以 30 倍以上数据建立的旧 SOTA。
–

Overlaying Governance: A Compositional Authorization Framework for Delegation and Scope in Agentic AI13arxiv.org原文 ↗
提出 agentic AI 的组合式授权框架,认为 OAuth 式静态 consent token 不足以表达递归委托、动态 scope 和责任边界。论文定义 delegation 类型、权限与 accountability 影响,并引入 resource scope attenuation 来缩小 agent 访问 envelope。它还给出 overlay operator,把递归委托链等新语义叠加到已有 relational policies 上,而不要求重写原授权域。它的看点是把 agent 权限治理写成可组合的形式化对象。
–

AI Agents Enable Adaptive Computer Worms14arxiv.org原文 ↗
安全与攻防系统·基础设施
展示 AI agent 可能把传统蠕虫从固定漏洞利用推向针对每个目标生成定制攻击策略的形态。论文以 WannaCry 这类预设漏洞路径为对照,强调 patch 单一漏洞无法覆盖 agent 自动枚举环境、推理弱点和生成利用方案的风险。它属于安全威胁建模类工作,不是普通 malware 工程复现。值得读的是它把 agent autonomy 带来的攻击面变化讲得很直接。
–

Agent libOS: A Library-OS-Inspired Runtime for Long-Running, Capability-Controlled LLM Agents15arxiv.org原文 ↗
提出 Agent libOS,把长期运行 LLM agent 抽象成 AgentProcess,而不是一次请求-响应调用。运行时包含 process identity、parent-child lineage、lifecycle state、AgentImage 派生的 tool table、typed Object Memory、显式 capabilities、human queues、checkpoints、events 和 audit records。作者明确它不实现硬件驱动、kernel isolation 或 POSIX OS,而是运行在常规 host OS 之上的 library-OS substrate。它给 agent 的恢复、审计和权限边界提供了一套系统软件词汇。
–

KVarN: Variance-Normalized KV-Cache Quantization Mitigates Error Accumulation in Reasoning Tasks16arxiv.org原文 ↗
针对长 horizon reasoning decoding 中 KV-cache 量化误差随时间积累的问题,提出 calibration-free 的 KVarN。方法先做 Hadamard rotation,再对 K/V 矩阵双轴做 variance normalization,以修正 outlying token-scale errors。论文报告在 MATH500、AIME24 和 HumanEval 等 generative benchmark 上,2-bit precision 达到新的 KV-cache quantization SOTA,并提供 vLLM 实现。它提醒大家 prefill-like 评测不足以代表真实 autoregressive decoding 误差。
–

Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories17arxiv.org原文 ↗
提出受人类睡眠启发的持续学习范式,让模型把短期 in-context 记忆蒸馏进更稳定的长期参数。论文描述了 Sleep、replay consolidation 和 Dreaming 递归改进过程,用于弥合即时预测能力与长期知识转移之间的差距。它不是单纯外部 memory 检索,而是讨论 self-modification 与参数层 consolidation。这个方向的风险和评估都还会很难,但问题定义本身值得关注。
–
开源 / 项目 · Projects
15 项 · 开源 / 项目
Self-hosted dev sandboxes with preview URLs19github.com原文 ↗
执行环境与沙箱编码
该项目提供自托管开发沙箱:每个沙箱是带 shell、Node、Python、git 和常用工具的 Docker 容器,并自动获得 HTTPS preview URL。公开说明强调它不依赖 Kubernetes,而是 Go control plane、SQLite state 和 Traefik 路由;沙箱 idle 时停止,下一次 HTTP 请求唤醒,workspace 可跨停止和重启持久化。安全侧包括 dropped capabilities、no-new-privileges、read-only rootfs、内存与 PID 限制。它适合需要 AI agent 隔离构建和预览代码的单机部署场景。
–
CLI for crawling documentation sites into Markdown with defuddle20github.com原文 ↗
Docrawl 是把文档站抓取并转换成 Markdown 的 CLI,digest 指向其使用 defuddle 清理网页主体内容。Defuddle 本身负责去掉 sidebar、header 等 clutter,输出更适合阅读和转 Markdown 的 clean HTML。这个组合的工程点在于把 docs crawling 和内容抽取打包为本地工具,而不是只给 agent 原始网页。对 RAG 或 agent docs ingestion 来说,干净 Markdown 通常比完整 HTML 更容易检索和压缩。
–


Moxie Docs22moxiedocs.com原文 ↗
Moxie Docs 为 GitHub repo 建立 living index,把源代码、测试、文档和历史整理成人可读文档与 agent 可读 MCP context。主页写明每次 merge 后会保持索引更新,提供 source-cited docs、repo conventions、doc gaps 和 verified commands;Starter 计划覆盖 3 个私有 repo、每 repo 1,000 indexed files,Team 计划覆盖 10 个 repo、每 repo 5,000 files。它的重点是把代码库约定放到 agent 上下文,而不是把半个 repo 粘进提示词。
–
Agent-browser-shield23github.com原文 ↗
Agent-browser-shield 是面向 web-browsing AI agents 的浏览器扩展,目标是降低页面误导、prompt injection 和错误操作风险。digest 信息显示它属于浏览器侧安全护栏,不是通用 agent runtime。它的技术价值在于把网页内容、DOM 操作和 agent 决策之间的风险点放到扩展层处理。随着 agent 直接读网页和点击页面变多,这类客户端防护会比事后日志审计更靠近风险源。
–
Ideogram 4.024github.com原文 ↗
github.com
Ideogram 4.0 是 9.3B open-weight text-to-image diffusion transformer,社区摘录显示它使用 34-layer DiT,并把 text/image tokens 放在同一 self-attention sequence 中。项目强调结构化 JSON prompting、文字渲染和空间控制,社区示例也提到 bounding box JSON prompt。它的开放权重意义在于把排版、文字和区域约束更强的图像模型放到可本地实验的范围内。对设计类生成模型来说,能否稳定控制文本和空间比单纯画质更关键。
–
Solving complex optimization problems with Google OR-Tools in browser25github.com原文 ↗
github.com
or-tools-wasm 把 Google OR-Tools 编译到 TypeScript/WASM,让优化问题可在浏览器本地求解。相关说明称它主要面向 browser runtime,本地运行,不必把模型或约束上传到服务端。这个项目的实用点在于把 CP-SAT/组合优化能力带入前端交互应用。对教学、排班、路径和配置类工具来说,WASM 版本能降低部署门槛。
–
Extract27extract.page原文 ↗
检索与知识接地数据·分析
Extract 是 hosted document extraction API,用于把 PDF 等文档抽取为结构化文本、表格、图片和 layout 信息。页面说明它返回 structured spans、bounding boxes 和 font metadata,图片会上传到 object store 并以 image_url 返回;示例 API 支持通过 URL 提交 PDF。它对 RAG 的价值在于保留文档结构,而不只是输出连续纯文本。对于表格密集或版式重要的 PDF,坐标和字体元数据能显著改善后续检索与引用。
–

Paseo30github.com原文 ↗
Paseo 是 coding agent interface,支持从手机、桌面和 CLI 管理 Claude Code、Codex、Copilot、OpenCode 和 Pi agents。README 摘要显示它运行本地 daemon,负责 agent process orchestration、WebSocket API 和 MCP server;CLI 可安装为 @getpaseo/cli。它把 provider adapter、session 管理和远程控制统一到一个本地服务。项目看点在于让多种 coding harness 共用一个会话操作层。
–
LiteHarness32github.com原文 ↗
LiteHarness 用单一 SDK 调用 Claude Agent、OpenAI Agent、Pi AI 等 coding-agent harnesses。相邻 LiteLLM Agent Platform 文档显示该生态关注让 coding agents 在隔离沙箱中运行,并通过 vault/proxy 避免真实密钥暴露给 agent。LiteHarness 的意义在于把不同 harness 的启动、调用和结果接口标准化。随着 coding agent 数量增加,统一适配层会降低评测和生产集成成本。
–
行业动态 · Industry News
14 项 · 行业动态Introducing new capabilities to GPT-Rosalind33openai.com原文 ↗
OpenAI 更新 GPT-Rosalind 的生命科学能力,覆盖生物推理、药物化学、基因组分析和实验工作流。此前 GPT-Rosalind 作为 research preview 面向合格客户在 ChatGPT、Codex 和 API 中提供,并配套 Codex 的 Life Sciences research plugin,连接 50 多个科学工具和数据源。它的关键点是把 domain model 放入长流程、工具密集的科研工作,而不是只做单题问答。
–
OpenAI public policy agenda34openai.com原文 ↗
openai.com
OpenAI 在 2026-06-03 发布公共政策议程,围绕 safety、youth safety、AI resilience、workforce transition、content provenance、AI infrastructure and energy 展开。文中支持围绕 California SB 53、New York RAISE Act、Illinois SB 315 等州级 frontier safety 法案形成联邦框架,并强调 CAISI 的评估和标准角色。它是一份政策立场集合,反映 OpenAI 希望监管从州级共识走向联邦统一。
–
A blueprint for democratic governance of frontier AI35openai.com原文 ↗
openai.com
OpenAI 同日发布 frontier AI 治理蓝图,主张美国建立耐久的联邦治理框架。蓝图分三部分:利用州级 frontier safety law 的共识、强化 CAISI 作为美国 frontier AI safety 机构、动员政府层面的 national security 和 public safety resilience plan。它把 frontier safety 从公司自律叙事转为制度设计议题。
–
Gemma 4 12B: A unified, encoder-free multimodal model36blog.google原文 ↗
blog.google
Google 发布 Gemma 4 12B,定位为 unified、encoder-free 的 multimodal model,并以 Apache 2.0 license 开放。公开摘录称它让图像和音频输入更直接进入模型 token 空间,减少传统多模态系统里的独立 encoder 带来的延迟和内存开销。对于本地模型生态,12B 规模和 16GB 级设备可运行的叙事会推动更多端侧多模态实验。
–
MAI-Code-1-Flash37microsoft.ai原文 ↗
microsoft.ai
Microsoft 发布 MAI-Code-1-Flash,面向 GitHub Copilot 和 VS Code 的代码模型。digest 信息显示它是 Microsoft MAI 系列里的代码向发布,重点落在 IDE 和 coding assistant 工作流。与通用聊天模型相比,这类模型的竞争点会是补全、编辑、agentic coding 和低延迟交互。它也说明大厂正在把 coding model 做成产品内专用能力,而不仅是 API 模型名。
–
Elixir v1.20: Now a gradually typed language38elixir-lang.org原文 ↗
elixir-lang.org
Elixir 1.20 发布,并把 gradual typing 作为核心更新方向。digest 指出这次版本使 Elixir 成为 gradually typed language,这意味着类型能力会在动态语言生态中逐步进入日常开发而非一次性强制迁移。对 BEAM 社区来说,关键看类型标注、推断和工具链如何服务大型代码库。
–
Kotlin 2.4.0 Released39blog.jetbrains.com原文 ↗
blog.jetbrains.com
JetBrains 发布 Kotlin 2.4.0。digest 没列具体 changelog,但 Kotlin 版本发布通常涉及 compiler、language features、multiplatform、IDE 和 Gradle tooling 的组合更新。它值得关注的是 Kotlin 在 JVM、Android 与 multiplatform 之间持续协调兼容性和开发体验。对团队升级来说,重点会落在编译器行为、依赖插件和构建链适配。
–
Angular v2240blog.angular.dev原文 ↗
blog.angular.dev
Angular v22 发布,包含框架和开发体验更新。digest 未展开细项,因此正文只按发布事实处理:这是 Angular 主版本迭代,通常会影响 compiler、signals、SSR/hydration、router 和 tooling 生态。对大型前端项目,主版本升级的成本通常不在单个 API,而在依赖链和工程约定同步。
–
A Post-Quantum Future for Let's Encrypt41letsencrypt.org原文 ↗
letsencrypt.org
Let’s Encrypt 介绍后量子证书路径和迁移计划。此类迁移牵涉 CA、浏览器、服务器、中间设备和自动化续期系统,不是单个加密算法切换。它的重要性在于公有 Web PKI 必须在量子安全、兼容性、证书大小和部署节奏之间权衡。对运维侧,后量子证书最终会影响 TLS 性能和自动化证书管理。
–
DaVinci Resolve 2142blackmagicdesign.com原文 ↗
blackmagicdesign.com
Blackmagic Design 发布 DaVinci Resolve 21 新功能页面。digest 没列完整功能,但 Resolve 作为剪辑、调色、Fusion、Fairlight 和协作工作流合一工具,每次大版本都会影响专业视频制作 pipeline。值得关注的是 AI 辅助、媒体管理和性能相关更新如何进入真实剪辑环境。它属于创作者工具链的生产力升级,而非模型新闻。
–
Meta workers can opt out of being tracked at work up to 30 min43bbc.com原文 ↗
bbc.com
BBC 报道 Meta 员工每天最多可选择 30 分钟不被工作场所 tracking。该新闻的关键事实是 opt-out 时间上限为 30 分钟,议题集中在雇主监控、员工隐私和工作场所数据治理。它不直接是 AI 技术发布,但与企业数据采集边界、劳动监管和透明度有关。
–
32GB of DDR5 now costs $37544tomshardware.com原文 ↗
tomshardware.com
Tom’s Hardware 报道 32GB DDR5 价格最低已到 375 美元,原因指向 AI 需求和供应紧张继续挤压 PC 装机市场。这个数字说明内存不再只是小幅波动的配件成本,而可能成为本地 AI、游戏和工作站预算里的主要变量。对消费者和小团队,硬件价格会直接影响本地模型实验门槛。
–
Alphabet announces $80B equity capital raise to expand AI infra and compute45abc.xyz原文 ↗
abc.xyz
Alphabet 宣布拟进行 800 亿美元股权融资,用于扩展 AI infrastructure 和 compute。这个规模本身就是关键信息,显示 AI 竞争正在通过资本市场直接转化为数据中心、芯片和能源支出。它对行业的含义不是某个产品马上变化,而是基础设施资本开支继续上行。
–
Shopify Is Down46shopifystatus.com原文 ↗
shopifystatus.com
Shopify status 页面显示服务故障事件。状态页类新闻的关键在于影响面和恢复节奏,digest 未给出具体 incident 时间线,因此只能按服务中断事实处理。对电商平台来说,短时间故障也会影响支付、店铺后台、订单处理和商家客服。它提醒依赖 SaaS 平台的业务需要关注状态订阅和降级预案。
–
博客文章 · Blog Posts
10 项 · 博客文章
Uber's $1,500/month AI limit is a useful signal for AI tool pricing47simonwillison.net原文 ↗
simonwillison.net
Simon Willison 记录 Uber 对员工 AI 工具使用设置每月 1,500 美元上限,并将其视为 AI tool pricing 的真实信号。这个数字重要,因为 coding agents 和高频推理工具的成本已经高到需要组织级预算控制,而不是个人订阅层面的零散费用。文章的看点在于把 agent 使用量、内部 chargeback 和供应商定价联系起来。
–
Microsoft's new MAI models48simonwillison.net原文 ↗
simonwillison.net
Simon Willison 汇总 Microsoft 新 MAI text/code models 的参数规模、用途和发布信息。digest 指向 MAI 模型家族,尤其与 MAI-Code-1-Flash 这类 IDE 内代码模型相关。文章价值在于把官方发布拆成模型定位、产品入口和可用性信息,方便判断哪些是研究模型,哪些已经进入 Copilot/VS Code。
–
datasette-agent-micropython 0.1a049simonwillison.net原文 ↗
执行环境与沙箱数据·分析
Simon Willison 发布 Datasette Agent 的 MicroPython sandbox alpha,用 WASM 执行 Python 代码。这个方向把 agent 可运行代码限制在更小、更可控的解释器环境里,适合数据分析和插件实验。它的关键不是性能,而是用 WASM sandbox 给 agent 代码执行提供边界。
–
micropython-wasm 0.1a150simonwillison.net原文 ↗
执行环境与沙箱系统·基础设施
micropython-wasm 0.1a1 是 Simon Willison 为 sandbox 实验推进的 alpha 更新,digest 指出它修复了先前限制。MicroPython + WASM 的组合使浏览器或受限 runtime 中运行 Python 片段更可控。它与 datasette-agent-micropython 一起构成了 agent 安全执行小工具链。
–

The Sequence AI of the Week #871: Inside the Loop with Claude Opus 4.851thesequence.substack.com原文 ↗
TheSequence 讨论 Claude Opus 4.8 在 agent 和 coding 场景中的行为变化。digest 没给出细节,因此正文只按文章主题处理:它关注模型在 loop 内执行、工具调用和代码任务中的表现,而不是静态 benchmark。此类评论的价值在于观察 agent 行为的质感变化,例如坚持性、错误恢复和上下文处理。
–
Microsoft Build: MAI-Thinking-1 and MAI Family models, Surface RTX Spark Dev Box, and OpenClaw in Windows52news.smol.ai原文 ↗
smol.ai 汇总 Microsoft Build 上 MAI-Thinking-1、MAI family models、Surface RTX Spark Dev Box 和 Windows agent 生态发布。它把模型、开发硬件和 OpenClaw/Windows agent 集成放在同一脉络里,说明 Microsoft 的路线不只是发布模型,而是补齐本地开发、agent runtime 和 IDE 入口。对开发者,价值在于一页看到 Build 相关 AI 基础设施更新。
–

Pwnd Blaster: Hacking your PC using your speaker without ever touching it53blog.nns.ee原文 ↗
blog.nns.ee
这篇安全研究展示通过扬声器相关路径触发 PC 攻击的实验。digest 将其描述为不用接触电脑、经由 speaker 触发的攻击链,属于硬件/外设信任边界的案例。它值得读的地方在于攻击面不在常规网络入口,而在用户通常不会纳入威胁模型的声音或外设通道。
–
1-Click GitHub Token Stealing via a VSCode Bug54blog.ammaraskar.com原文 ↗
安全与攻防编码
Ammar Askar 披露一个可导致 GitHub token 被窃取的 VS Code bug。标题中的 1-click 表明交互门槛很低,风险集中在 IDE、扩展或链接处理链路如何暴露开发者凭证。它对 coding-agent 时代尤其重要,因为 agent、IDE 和 GitHub token 的权限常常叠在同一个工作站里。
–

Every Byte Matters55fzakaria.com原文 ↗
fzakaria.com
Farid Zakaria 写软件体积、依赖和字节级优化取舍。digest 显示文章关注每个 byte 的成本,这类讨论通常反对把依赖膨胀视作无关紧要。它的实际价值在于提醒工程师:包体、冷启动、缓存、传输和部署成本会在规模化后变成真实约束。
–

{kind=link}
Now AI agents need what RSS does56julienreszka.com原文 ↗
Julien Reszka 讨论 RSS 作为 agent 可读信息接口的作用。文章核心是:AI agents 需要稳定、可订阅、结构化的信息源,而 RSS 已经提供了类似能力。它把 RSS 从人类阅读器时代的遗产,重新解释为 agent 获取更新、追踪站点和减少网页抓取噪音的基础协议。
–
GitHub 热门 · GitHub Trending
10 项 · GitHub 热门本期重点chopratejas/headroom5github.com原文 ↗
Headroom 压缩 agent 读取的 tool outputs、logs、files 和 RAG chunks,定位为 library、proxy、ASGI middleware、callback 和 MCP server。README 称典型上下文中 70-95% 是 boilerplate,项目目标是在进入 LLM 前压缩掉这些冗余,并支持 LangChain、LangGraph、Agno、Strands、LiteLLM 和 MCP。它的关键数字是 60-95% fewer tokens。对 tool-heavy agent 来说,这是直接作用在成本和 context window 上的 runtime 层。
–
supermemoryai/supermemory57github.com原文 ↗
Supermemory 是面向 AI 应用的 memory 和 context layer,README 称其在 LongMemEval、LoCoMo 和 ConvoMem 三个 memory benchmark 上排名第一。它提供 fact extraction、user profiles、hybrid search、connectors 和 multimodal extractors;用户画像调用约 50ms。项目把 RAG、个人记忆、知识更新、矛盾处理和自动遗忘放进一个 API。它的看点是 memory 不只是向量库,而是带时间和用户建模的上下文系统。
–
modelscope/FunASR58github.com原文 ↗
工具使用其他垂直
FunASR 是工业级语音识别工具包,README 摘要列出 ASR、VAD、标点恢复、语言模型、说话人验证、说话人分离、多说话人 ASR、情绪识别、streaming 和 OpenAI-compatible API。项目标题称支持 50+ languages、170x realtime。它的价值在于把语音前处理、识别和服务接口集中在一个开源工具包里。对实时语音 agent,streaming 与兼容 API 比单模型精度同样关键。
–
本期重点NVIDIA/OpenShell4github.com原文 ↗
OpenShell 是 NVIDIA 面向 autonomous AI agents 的安全、私有 runtime。README 摘要称它通过 sandboxed execution environments 保护数据、凭证和基础设施,并用 declarative YAML policies 阻止未授权文件访问、数据外泄和 uncontrolled network activity。NVIDIA 技术博客还把它描述为 out-of-process policy enforcement、sandboxing、granular permissions 和 privacy router 的组合。它的技术看点是把 agent 权限从提示词约束下沉到运行时边界。
–
agentgateway/agentgateway59github.com原文 ↗
agentgateway 是开源 HTTP/gRPC gateway,把传统应用流量和 AI-native protocols 放在同一 data plane。项目站点说明它可 route、secure、observe、govern services、LLM provider traffic、MCP tools 和 agent-to-agent communication,并支持 OpenAI、Claude、Gemini 或自托管模型的 credentialing 与 failover。它的重点是平台团队可用的统一控制面,而不是单一 MCP proxy。随着 agent 通信协议增多,网关层会成为治理和观测的集中入口。
–
EricLBuehler/mistral.rs60github.com原文 ↗
github.com
mistral.rs 是 Rust 编写的跨平台 LLM inference engine,支持 text、vision、image generation 和 speech。README 摘要列出 Rust SDK、Python package、OpenAI-compatible HTTP server、Responses API、MCP server,并有 Anthropic-compatible endpoint 相关文档。它适合想在 Rust 生态里做本地或服务端推理的人。项目看点在于模型覆盖、API 兼容和性能工程三者并行。
–
googleworkspace/cli61github.com原文 ↗
Google Workspace CLI 用一个 `gws` 命令覆盖 Drive、Gmail、Calendar、Sheets、Docs、Chat、Admin 等 API,并由 Google Discovery Service 动态构建。README 摘要称它包含 100+ Agent Skills,一个支持 API 对应一个 SKILL.md,另有 50 个 Gmail、Drive、Docs、Calendar、Sheets 的 curated recipes。它把 Workspace 操作变成 agent 可安装技能。对企业 agent 来说,这比让模型临时拼 REST 调用可靠得多。
–
HelixDB/helix-db62github.com原文 ↗
HelixDB 是 Rust 写的 open-source graph-vector database,主打把 application DB、vector DB、graph DB 和应用层的一部分合并到单一平台。README 摘要说它以 graph + vector data model 为主,也支持 KV、documents 和 relational data;内置 MCP tools 让 agents 能发现数据、沿图遍历,而不是生成给人读的查询。它对 AI memory 和 knowledge graph 的吸引力在于图遍历与向量相似度同场。
–
nanocoai/nanoclaw63github.com原文 ↗
NanoClaw 是轻量 OpenClaw 替代项目,把 agents 跑在容器里并连接 WhatsApp、Telegram、Discord、Slack、Teams、iMessage、Matrix、Google Chat、Webex、Linear、GitHub、WeChat 和 email。README 摘要称它基于 Anthropic Claude Agent SDK,凭证不进入容器,而是通过 OneCLI Agent Vault 在 proxy 层注入,并支持 rate limits 和 access policies。它把个人助理、消息入口和容器隔离结合起来。看点是轻量化能否保持足够的安全边界。
–
mksglu/context-mode64github.com原文 ↗
Context Mode 是 MCP server 和 CLI proxy,作为 AI coding assistants 与 context window 之间的 sandboxed execution/indexing layer。公开摘要称它拦截 Bash、WebFetch、Read 等 tool calls,在隔离 subprocess 中运行,把 raw output 索引进 SQLite FTS5,再只返回 BM25-ranked snippets。第三方资料称它可把多步 coding loop 的 token spend 降低 60-98%。它与 Headroom 同属 context optimization runtime,但更强调工具输出沙箱化和会话连续性。
–
引用来源 · References
64 条 · 引用- 1 Adaptive Auto-Harness: Sustained Self-Improvement for Agentic System Deployment on Open-Ended Task Streams. arXiv:2606.01770https://arxiv.org/abs/2606.01770 ↩ 回到正文 · back to text
- 2 Handoff Debt: The Rediscovery Cost When Coding Agents Take Over Interrupted Tasks. arXiv:2606.02875https://arxiv.org/abs/2606.02875 ↩ 回到正文 · back to text
- 3 ToolGate: Token-Efficient Pre-Call Control for Tool-Augmented Vision-Language Agents. arXiv:2606.03054https://arxiv.org/abs/2606.03054 ↩ 回到正文 · back to text
- 4 NVIDIA/OpenShell. GitHub: NVIDIA/OpenShellhttps://github.com/NVIDIA/OpenShell ↩ 回到正文 · back to text
- 5 chopratejas/headroom. GitHub: chopratejas/headroomhttps://github.com/chopratejas/headroom ↩ 回到正文 · back to text
- 6 What Benchmarks Don't Measure: The Case for Evaluating Abstention Competence in Autonomous Agents. arXiv:2606.02965https://arxiv.org/abs/2606.02965 ↩ 回到正文 · back to text
- 7 Inducing Reasoning Primitives from Agent Traces. arXiv:2606.02994https://arxiv.org/abs/2606.02994 ↩ 回到正文 · back to text
- 8 SkillDAG: Self-Evolving Typed Skill Graphs for LLM Skill Selection at Scale. arXiv:2606.03056https://arxiv.org/abs/2606.03056 ↩ 回到正文 · back to text
- 9 DELTAMEM: Incremental Experience Memory for LLM Agents via Residual Trees. arXiv:2606.03083https://arxiv.org/abs/2606.03083 ↩ 回到正文 · back to text
- 10 DeskCraft: Benchmarking Desktop Agents on Professional Workflows and Human-in-the-Loop Collaboration. arXiv:2606.03103https://arxiv.org/abs/2606.03103 ↩ 回到正文 · back to text
- 11 InfoMem: Training Long-Context Memory Agents with Answer-Conditioned Information Gain. arXiv:2606.03329https://arxiv.org/abs/2606.03329 ↩ 回到正文 · back to text
- 12 What Makes Interaction Trajectories Effective for Training Terminal Agents?. arXiv:2606.03461https://arxiv.org/abs/2606.03461 ↩ 回到正文 · back to text
- 13 Overlaying Governance: A Compositional Authorization Framework for Delegation and Scope in Agentic AI. arXiv:2606.03518https://arxiv.org/abs/2606.03518 ↩ 回到正文 · back to text
- 14 AI Agents Enable Adaptive Computer Worms. arXiv:2606.03811https://arxiv.org/abs/2606.03811 ↩ 回到正文 · back to text
- 15 Agent libOS: A Library-OS-Inspired Runtime for Long-Running, Capability-Controlled LLM Agents. arXiv:2606.03895https://arxiv.org/abs/2606.03895 ↩ 回到正文 · back to text
- 16 KVarN: Variance-Normalized KV-Cache Quantization Mitigates Error Accumulation in Reasoning Tasks. arXiv:2606.03458https://arxiv.org/abs/2606.03458 ↩ 回到正文 · back to text
- 17 Language Models Need Sleep: Learning to Self-Modify and Consolidate Memories. arXiv:2606.03979https://arxiv.org/abs/2606.03979 ↩ 回到正文 · back to text
- 18 Mnemo. GitHub: zaydmulani09/mnemohttps://github.com/zaydmulani09/mnemo ↩ 回到正文 · back to text
- 19 Self-hosted dev sandboxes with preview URLs. GitHub: tastyeffectco/sandboxeshttps://github.com/tastyeffectco/sandboxes ↩ 回到正文 · back to text
- 20 CLI for crawling documentation sites into Markdown with defuddle. GitHub: artemnistuley/docrawlhttps://github.com/artemnistuley/docrawl ↩ 回到正文 · back to text
- 21 Viewport. GitHub: Brumbelow/viewporthttps://github.com/Brumbelow/viewport ↩ 回到正文 · back to text
- 22 Moxie Docs. Web: moxiedocs.comhttps://moxiedocs.com ↩ 回到正文 · back to text
- 23 Agent-browser-shield. GitHub: pixiebrix/agent-browser-shieldhttps://github.com/pixiebrix/agent-browser-shield ↩ 回到正文 · back to text
- 24 Ideogram 4.0. GitHub: ideogram-oss/ideogram4https://github.com/ideogram-oss/ideogram4 ↩ 回到正文 · back to text
- 25 Solving complex optimization problems with Google OR-Tools in browser. GitHub: Axelwickm/or-tools-wasmhttps://github.com/Axelwickm/or-tools-wasm ↩ 回到正文 · back to text
- 26 Division Swarm. GitHub: division-sh/swarmhttps://github.com/division-sh/swarm ↩ 回到正文 · back to text
- 27 Extract. Web: extract.pagehttps://extract.page ↩ 回到正文 · back to text
- 28 Chatcode. Web: chatcode.devhttps://chatcode.dev/ ↩ 回到正文 · back to text
- 29 OpenSOP. Web: opensop.aihttps://opensop.ai/ ↩ 回到正文 · back to text
- 30 Paseo. GitHub: getpaseo/paseohttps://github.com/getpaseo/paseo ↩ 回到正文 · back to text
- 31 Carto. GitHub: theanshsonkar/cartohttps://github.com/theanshsonkar/carto ↩ 回到正文 · back to text
- 32 LiteHarness. GitHub: LiteLLM-Labs/lite-harnesshttps://github.com/LiteLLM-Labs/lite-harness ↩ 回到正文 · back to text
- 33 Introducing new capabilities to GPT-Rosalind. OpenAIhttps://openai.com/index/introducing-new-capabilities-to-gpt-rosalind ↩ 回到正文 · back to text
- 34 OpenAI public policy agenda. OpenAIhttps://openai.com/index/public-policy-agenda ↩ 回到正文 · back to text
- 35 A blueprint for democratic governance of frontier AI. OpenAIhttps://openai.com/index/frontier-safety-blueprint ↩ 回到正文 · back to text
- 36 Gemma 4 12B: A unified, encoder-free multimodal model. Googlehttps://blog.google/innovation-and-ai/technology/developers-tools/introducing-gemma-4-12b/ ↩ 回到正文 · back to text
- 37 MAI-Code-1-Flash. Microsoft AIhttps://microsoft.ai/news/introducingmai-code-1-flash/ ↩ 回到正文 · back to text
- 38 Elixir v1.20: Now a gradually typed language. Elixirhttps://elixir-lang.org/blog/2026/06/03/elixir-v1-20-0-released/ ↩ 回到正文 · back to text
- 39 Kotlin 2.4.0 Released. JetBrainshttps://blog.jetbrains.com/kotlin/2026/06/kotlin-2-4-0-released/ ↩ 回到正文 · back to text
- 40 Angular v22. Angular Bloghttps://blog.angular.dev/announcing-angular-v22-c52bb83a4664 ↩ 回到正文 · back to text
- 41 A Post-Quantum Future for Let's Encrypt. Let's Encrypthttps://letsencrypt.org/2026/06/03/pq-certs ↩ 回到正文 · back to text
- 42 DaVinci Resolve 21. Blackmagic Designhttps://www.blackmagicdesign.com/products/davinciresolve/whatsnew ↩ 回到正文 · back to text
- 43 Meta workers can opt out of being tracked at work up to 30 min. BBChttps://www.bbc.com/news/articles/c93x0k194yno ↩ 回到正文 · back to text
- 44 32GB of DDR5 now costs $375. Tom's Hardwarehttps://www.tomshardware.com/pc-components/ddr5/32gb-of-ddr5-now-costs-usd375-minimum-ai-shortage-continues-to-squeeze-pc-building ↩ 回到正文 · back to text
- 45 Alphabet announces $80B equity capital raise to expand AI infra and compute. Alphabet Investor Relationshttps://abc.xyz/investor/news/news-details/2026/Alphabet-Announces-Proposed-80-Billion-Equity-Capital-Raise-to-Expand-AI-Infrastructure-and-Compute-2026-b0myAMewCa/default.aspx ↩ 回到正文 · back to text
- 46 Shopify Is Down. Shopify Statushttps://www.shopifystatus.com ↩ 回到正文 · back to text
- 47 Uber's $1,500/month AI limit is a useful signal for AI tool pricing. Simon Willisonhttps://simonwillison.net/2026/Jun/3/uber-caps-usage/ ↩ 回到正文 · back to text
- 48 Microsoft's new MAI models. Simon Willisonhttps://simonwillison.net/2026/Jun/2/microsofts-new-models/#atom-everything ↩ 回到正文 · back to text
- 49 datasette-agent-micropython 0.1a0. Simon Willisonhttps://simonwillison.net/2026/Jun/2/datasette-agent-micropython/#atom-everything ↩ 回到正文 · back to text
- 50 micropython-wasm 0.1a1. Simon Willisonhttps://simonwillison.net/2026/Jun/2/micropython-wasm/#atom-everything ↩ 回到正文 · back to text
- 51 The Sequence AI of the Week #871: Inside the Loop with Claude Opus 4.8. TheSequencehttps://thesequence.substack.com/p/the-sequence-ai-of-the-week-871-inside ↩ 回到正文 · back to text
- 52 Microsoft Build: MAI-Thinking-1 and MAI Family models, Surface RTX Spark Dev Box, and OpenClaw in Windows. smol.aihttps://news.smol.ai/issues/26-06-02-msft-mai-2/ ↩ 回到正文 · back to text
- 53 Pwnd Blaster: Hacking your PC using your speaker without ever touching it. nns.eehttps://blog.nns.ee/2026/06/03/katana-badusb/ ↩ 回到正文 · back to text
- 54 1-Click GitHub Token Stealing via a VSCode Bug. Ammar Askarhttps://blog.ammaraskar.com/github-token-stealing/ ↩ 回到正文 · back to text
- 55 Every Byte Matters. Farid Zakariahttps://fzakaria.com/2026/06/01/every-byte-matters ↩ 回到正文 · back to text
- 56 Now AI agents need what RSS does. Julien Reszkahttps://julienreszka.com/blog/rss-is-back-ai-agents-are-reading-it/ ↩ 回到正文 · back to text
- 57 supermemoryai/supermemory. GitHub: supermemoryai/supermemoryhttps://github.com/supermemoryai/supermemory ↩ 回到正文 · back to text
- 58 modelscope/FunASR. GitHub: modelscope/FunASRhttps://github.com/modelscope/FunASR ↩ 回到正文 · back to text
- 59 agentgateway/agentgateway. GitHub: agentgateway/agentgatewayhttps://github.com/agentgateway/agentgateway ↩ 回到正文 · back to text
- 60 EricLBuehler/mistral.rs. GitHub: EricLBuehler/mistral.rshttps://github.com/EricLBuehler/mistral.rs ↩ 回到正文 · back to text
- 61 googleworkspace/cli. GitHub: googleworkspace/clihttps://github.com/googleworkspace/cli ↩ 回到正文 · back to text
- 62 HelixDB/helix-db. GitHub: HelixDB/helix-dbhttps://github.com/HelixDB/helix-db ↩ 回到正文 · back to text
- 63 nanocoai/nanoclaw. GitHub: nanocoai/nanoclawhttps://github.com/nanocoai/nanoclaw ↩ 回到正文 · back to text
- 64 mksglu/context-mode. GitHub: mksglu/context-modehttps://github.com/mksglu/context-mode ↩ 回到正文 · back to text