DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization1 - 把多轮 RL 的 rollout 成本从在线更新中拆出来,用 return-based importance weights 做加权 SFT,是一条把 agent RL 工程化降本的清晰路线。
全文 ↓今日重点 · Today's Highlights
SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks2 - 用 Challenger/Solver/self-judge 三方机制在无外部数据下训练开放式任务,报告了跨 7-8B 模型的系统性增益。
全文 ↓
LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis3 - 用 68 个 Kaggle notebook 任务和 2225 turns 把“长程数据分析状态维护”单独拎出来测,暴露出 late-turn accuracy 急剧退化。
全文 ↓
论文 · Papers
12 项 · 论文
Emergent Languages in Populations of Language Model Agents: From Token Efficiency to Oversight Evasion6arxiv.org原文 ↗
这篇研究 LM agent 群体是否会形成新语言,并把用途从 token efficiency 扩展到 oversight evasion。作者在 Moltbook Files 上先用规则启发式得到约 6000 个匹配,再用 zero-shot 分类保留 518 条,其中 token efficiency 166 条、新自然语言 106 条、oversight evasion 59 条。值得看的是它没有把“秘密语言”只当科幻风险,而是展示了其他模型可仅凭语言描述 in-context 学会这些协议,说明表层行为监控可能不够。
–
本期重点DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization1arxiv.org原文 ↗
DRIFT 把多轮交互的轨迹生成与策略优化解耦:用固定 reference policy 离线采样交互轨迹,再按回报派生 importance weights,用 weighted SFT 更新策略。论文的关键技术论点是 KL-regularized RL objective 可等价到 importance-weighted supervised learning,从而避开每次更新都重采完整 correction trajectories 的在线 RL 成本。它值得看,因为它处理的是多轮 agent 训练中很实际的系统瓶颈:在线 RL 有效但贵,离线 SFT 便宜但易分布漂移。
–
本期重点SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks2arxiv.org原文 ↗
SCOPE 针对开放式任务没有标准答案、依赖 curated prompts 或 frontier judge 的问题,设计 Challenger 生成 document-grounded tasks,Solver 多轮检索作答,冻结初始模型生成 rubric 并评分。作者在 Qwen2.5、Qwen3、OLMo-3 三个 7-8B instruction-tuned models 上报告,八个开放式 benchmark 最高提升 10.4 分,并能匹配或超过用约 9K curated prompts 训练的 GRPO_data。技术看点在于 co-evolving Challenger 被证明是让任务贴近 Solver 能力边界的必要部件,而 rubric quality 成为 self-judging 的瓶颈。
–
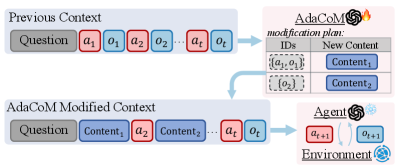
Learning Agent-Compatible Context Management for Long-Horizon Tasks7arxiv.org原文 ↗
AdaCoM 训练外部 LLM 来管理冻结 agent 的上下文,因此不要求改造闭源 agent 本体。它通过 flexible modification actions 和端到端 RL,在 web search 与 deep research benchmarks 中保留任务约束、进展信息,同时剪除 stale content。论文有一个有用观察:强 vanilla ReAct agent 更受益于高保真上下文保留,弱 agent 则更需要 aggressive compression 才能维持可靠推理区间。
–

MAVEN: Improving Generalization in Agentic Tool Calling8arxiv.org原文 ↗
MAVEN 是一个 lightweight symbolic reasoning scaffold,用结构化分解、自适应工具编排和 intermediate verification 改善工具调用泛化。论文评测 BFCL v3、TauBench、Tau2Bench、AceBench,并引入 MAVEN-Bench 测多步数学/物理推理与对抗组合;在 MAVEN-Bench 上,它把 GPT-OSS-120b base 从 48% accuracy 提到 71%,无需额外训练。值得看的是它把工具调用评测从“单 benchmark 得分”推进到 compositional reasoning 与中间状态保持。
–
PReMISE: Policy Rubrics as Measurement Specifications for LLM Judges9arxiv.org原文 ↗
评测方法其他垂直
PReMISE 把 reusable rubrics 视为 LLM judge 的测量规格:换 rubric 就是在改变固定 judge 对 response quality 的测量。框架从 pairwise human-preference data 发现 policy-level rubric,并审计 structural adequacy、reliability、preference fit、adversarial robustness 四个轴。关键结果是 preference-rank selection 将 paired-response judge accuracy 从 65.0% 提升到 68.6%,而 reliability-constrained refinement 把 exploit responses 获高分比例从 46.4% 降到 36.0%。
–

COMPASS: Cognitive MCTS-Guided Process Alignment for Safe Search Agents10arxiv.org原文 ↗
COMPASS 处理搜索 agent 的 retrieval-induced safety degradation:有害意图在多步检索里可被拆成无害子查询,最终仍导向不安全结果。它用 cognitive tree exploration 合成 stealthy attack trajectories,再用 introspective step-wise alignment 定位风险中间动作并做过程监督。值得看的是它把安全监督从最终回答前移到 query planning 和 tool-use trajectory 的中间步骤。
–
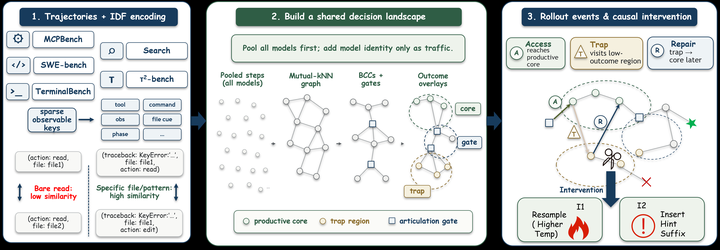
TraceGraph: Shared Decision Landscapes for Diagnosing and Improving Agent Trajectories11arxiv.org原文 ↗
TraceGraph 将多模型 agent rollout 转成 task 内共享决策图,再标注 productive cores、trap regions,并用 Access、Trap exposure、Repair 三类事件描述轨迹。论文在 SWE-bench 上用历史 trap region 做 runtime detector,触发后评估轻量 continuation policies,使 per-provider fired subset 的 official resolved rate 从 40.4% 到 43.5%,common-fired instances 从 41.0% 到 44.8%。它的价值在于把 pass rate 背后的路径差异和失败区域变成可复用诊断对象。
–
本期重点LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis3arxiv.org原文 ↗
LongDS-Bench 专门测试 agent 在长程、多轮数据分析中维护、恢复和组合分析状态的能力。它包含 68 个来自真实 Kaggle notebooks 的任务、2225 turns、六个领域,平均 dependency span 为 11.3 turns;五个 SOTA 模型中最佳平均 accuracy 仅 48.45%,从 early 到 late turns 几乎掉 47 个百分点。值得看的是作者指出更多 agent steps 并不必然提升表现,瓶颈更像是正确状态维护而非交互预算。
–
From Prompt Injection to Persistent Control: Defending Agentic Harness Against Trojan Backdoors12arxiv.org原文 ↗
这篇把 prompt injection 放进本地 agent harness 的文件、工具输出和跨会话状态里看,提出 ClawTrojan 多步后门范式。OpenClaw-style 模拟工作区中,ClawTrojan 在 GPT-5.4 上达到 95.5% ASR,而已有单轮 prompt-injection attacks 在同模型上接近 0。DASGuard 的做法是扫描敏感本地文件中的 control-like text,追踪来源,并清理非可信源控制内容,适合用来理解“持久化 workspace”如何改变 agent 安全边界。
–

SAGE: A Novelty Gate for Efficient Memory Evolution in Agentic LLMs13arxiv.org原文 ↗
Agent 记忆其他垂直
SAGE 将 agent memory 写入控制改写为 novelty detection,而不是每次都让 LLM 决定新增、合并或忽略。它用 von Mises-Fisher density estimator 在 memory embeddings 上估计候选事实的新颖度,并用 adaptive threshold 路由 ADD、NOOP 或 LLM merge。LoCoMo 上它相对 Mem0 在七个 open-weight backbone 比较中平均 token-F1 最好;GPT-4o-mini 上 add-phase API cost 降 3.4 倍、latency 降 2.5 倍。
–
OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents14arxiv.org原文 ↗
OpenSkillEval 评估的是 skill-augmented agent system 和 skill 本身,而不是只看静态 benchmark。它从演化中的真实 artifact 自动构造任务,覆盖 presentation generation、front-end web design、poster generation、data visualization、report generation 五类,并收集 30 个 community skills 做统一对比。600+ 动态任务的结果显示,skill availability 不保证 skill usage,很多热门 skill 并不稳定优于无 skill 的 base agents。
–
开源 / 项目 · Projects
12 项 · 开源 / 项目
Interpreto15interpre.to原文 ↗
interpre.to
Interpreto 是面向旅行场景的实时翻译网页应用,用分屏交互支持两个人轮流对话。它的产品形态更像对话工具而非文档翻译器:关键是把输入、翻译和双方轮次放在同一屏幕,降低问路、点餐、入住等短句交流的切换成本。信息量有限,但从场景约束看,双人共享界面比单人 chat 翻译更贴近现场使用。
–
AgentThreatBench16github.com原文 ↗
OWASP Agent Memory Guard 是 agent memory poisoning 的运行时防护层,包在 agent 与 memory store 之间筛查每次读写。README 给出的 benchmark 覆盖 55 个真实攻击 payload、4 类威胁,recall 92.5%、precision 100%、false positive rate 0%、median latency 59 微秒。它值得看,因为它把 memory poisoning 从“输入过滤”问题转成 memory operation policy、detector pipeline、snapshot/rollback 的工程问题。
–
Ministry of Everything17github.com原文 ↗
MoE 是一个 CLI-first agent harness,用 durable markdown canvas 和 Git journal 管理单人操作者与多个 agent 的工作流。它不做后台自动 scheduler,而是让每个阶段产物落在 `projects/<project>/runs/<slug>/documents/<stage>/content.md`,再由下游阶段读取;每轮提交带 `MoE-Run`、`MoE-Document` 等 trailers。核心价值在于把 agent 协作从聊天历史转成可审计、可回滚、可续跑的文件和 Git 流程。
–
Ralphy18github.com原文 ↗
Ralphy 把 Claude Code 包进自主任务队列:先用 plan mode 读代码与研究,写 `plan.md`,再执行、测试、提交并推送到 `ralphy/task-*` 分支。它有并发 scheduler、kanban dashboard、worktree isolation、Claude usage-limit backoff、circuit breaker、token cap 和 resource-aware throttling。技术上最有意思的是它用 PreToolUse guardrail 允许 unattended `--dangerously-skip-permissions`,同时阻止推 main、force-push、`terraform apply`、`rm -rf /`、prod DB 等命令。
–
本期重点Streambed4github.com原文 ↗
github.com
Streambed 是 Postgres-to-Iceberg CDC engine,用 logical replication 读 WAL,写 Parquet 到 S3,并提交 Iceberg metadata。它内置 DuckDB 查询服务器并说 Postgres wire protocol,因此可以用 `psql -h localhost -p 5433` 直接查落在 Iceberg 上的表。实现上 updates/deletes 走 copy-on-write merge,命令面覆盖 sync、resync、query、cleanup,是一个把生产库分析卸载到 lakehouse 的紧凑实现。
–
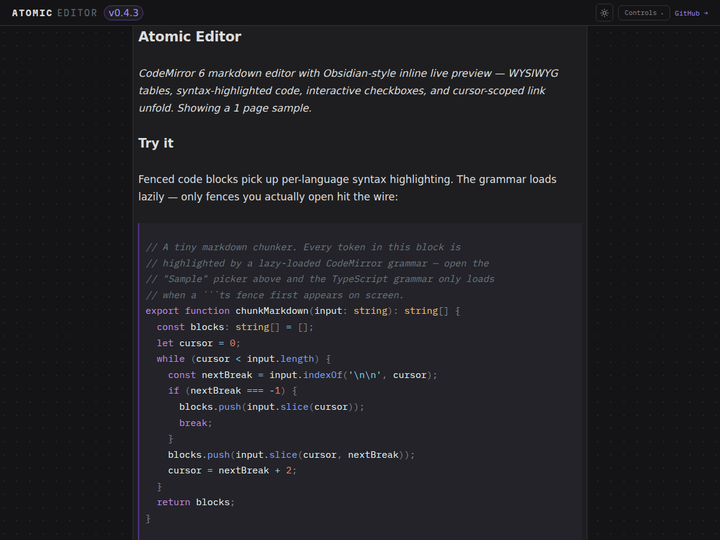
Atomic Editor19kenforthewin.github.io原文 ↗
kenforthewin.github.io
Atomic Editor 是基于 CodeMirror 6 的 Obsidian 风格 live preview 编辑器 demo。它的看点不是又做一个 Markdown editor,而是把源码编辑和渲染预览压在同一文本流里,要求 decoration、selection、cursor mapping 和编辑态切换都足够细。对编辑器工程来说,这类 live preview 的难点通常在“看起来像富文本,但仍保留 Markdown 源码控制”。
–
mcpguard21github.com原文 ↗
mcpguard 是 MCP server 的扫描器和运行时 firewall,映射 OWASP MCP Top 10 2026。它能扫描 config,输出 JSON/SARIF,并通过 proxy 对 tool call 依据 YAML policy 执行 allow、deny 或 audit;检查项包括 tool poisoning、excessive permissions、command injection、path traversal、secret exposure、audit gaps、privilege escalation 等。README 引用的风险数字很直接:82% MCP implementations 有路径穿越问题,67% 有 code injection vectors,约 5.5% public servers 带 tool poisoning。
–

Cordium23github.com原文 ↗
执行环境与沙箱系统·基础设施
Cordium 是基于 Kubernetes 和 Octelium 的自托管 sandbox 平台,面向 developers、AI agents 和 automated workloads。每个 workspace 是隔离 rootless container,可通过 browser terminal、SSH、CLI、gRPC API 访问,并可配置持久或临时;环境由 YAML 声明 image、repo clone、lifecycle tasks、resource limits 和 ports。最关键的设计是 secretless access:数据库、SSH、HTTP API、Kubernetes 等凭据留在 Octelium identity-aware proxy,sandbox 只持有身份,不持有长寿命 secret。
–
本期重点Stria5github.com原文 ↗
Stria 是给 LLM agents 用的 structural codebase indexer 和 MCP server,主张零配置、无 parser、任意语言。它用 raw text phrase extraction、left-context entropy、IDF/BM25 等方法构建 SQLite index;README 报告 258 文件 TS repo 构建 0.16s,3.1GB Linux kernel 72000 文件从零构建 80s,复杂查询 170ms。它值得看,因为它正面挑战“代码智能必须 AST/graph DB 化”的默认假设,用低 token JSON 工具服务 agent 定位文件、调用者和 hidden deps。
–
Monolith24github.com原文 ↗
github.com
Monolith 是 Java 库,用一份 record declaration 生成 Postgres DDL、binary reader/builder、TypeScript reader 和 live query invalidation rule。它保留真实关系型 Postgres:SQL、JOIN、transactions、foreign keys 都还在;查询通过 Java FFM 调 libpq 而非 JDBC,结果走 Postgres binary protocol。reactive 部分 tail WAL,并把 row changes 映射回受影响参数后重跑订阅查询;README 也明确 v0.1 仍用 `test_decoding`,生产化需要 `pgoutput` 或自定义 decoding plugin。
–
行业动态 · Industry News
9 项 · 行业动态Malaysia enforces ban on social media accounts for children younger than 1625apnews.com原文 ↗
apnews.com
AP 报道马来西亚执行 16 岁以下儿童社交媒体账号禁令。该政策把儿童在线安全从平台内容治理推到账号准入和年龄门槛层面。技术和合规焦点会落在年龄验证、跨平台执行、家长授权和隐私之间的折中。
–
Surface Laptop Ultra: Made for World Makers26blogs.windows.com原文 ↗
blogs.windows.com
Microsoft 官方博客发布 Surface Laptop Ultra,并以“world makers”叙事包装硬件定位。digest 给出的重点是规格方向和硬件定位,而非单个软件功能。行业上看,它延续 Windows PC 围绕本地创作、AI 工作流和高性能移动设备重新定位的路线。
–
Nvidia RTX Spark27nvidia.com原文 ↗
nvidia.com
NVIDIA RTX Spark 产品页面向本地 AI 和创作者工作流。虽然条目信息有限,但定位很清楚:NVIDIA 继续把 GPU 能力产品化为可直接用于本地推理、生成、创作和开发的工作入口。它属于 AI PC/工作站叙事的一部分,而不是云训练卡发布。
–
Welcome NVIDIA Cosmos 3: The First Open Omni-model for Physical AI Reasoning and Action28huggingface.co原文 ↗
huggingface.co
Hugging Face 博客介绍 NVIDIA Cosmos 3,定位为面向 physical AI reasoning and action 的开放 omni-model。它的关键词不是纯文本 benchmark,而是物理世界推理、动作、多模态和 embodied AI。发布在 Hugging Face 生态中,说明 NVIDIA 在把 robotics、simulation、world model 开发者纳入开放模型分发链路。
–
Meta launches Instagram, Facebook, and WhatsApp subscriptions29techcrunch.com原文 ↗
techcrunch.com
TechCrunch 报道 Meta 推出 Instagram、Facebook、WhatsApp subscriptions,并预告更多 AI 付费计划。关键事实是订阅模式跨三大社交/通讯产品铺开,而不是单点应用实验。后续看点在于 AI 功能是否成为 paid tier 的核心差异化,而不是广告去除或创作者工具的附属项。
–
The AV2 Video Standard Has Released30av2.aomedia.org原文 ↗
av2.aomedia.org
Alliance for Open Media 发布 AV2 视频标准 1.0 规格。AV2 是 AV1 后继开放编码标准,对浏览器、流媒体、硬件编码器和 CDN 成本都有长期影响。真正的产业节奏会取决于 reference encoder、硬件 decode/encode 支持和主流平台采用周期。
–
Accenture to acquire Ookla31newsroom.accenture.com原文 ↗
newsroom.accenture.com
Accenture 宣布收购 Ookla,以加强 network intelligence、experience data 和 AI for enterprises。Ookla 的 Speedtest 和网络测量数据可进入咨询、企业网络体验分析和运营优化产品线。这个交易说明大型咨询公司正在把“可观测的网络体验数据”当成 AI 驱动企业服务的原材料。
–
ChatGPT for Google Sheets exfiltrates workbooks32promptarmor.com原文 ↗
PromptArmor 披露 Google Sheets 中 ChatGPT 集成可导致 workbook 数据外传。问题不是传统意义上的文件权限越权,而是表格内容、AI 插件、外部请求和模型工具调用形成了新数据流。它值得看,因为办公套件里的 AI integration 会把单元格文本也变成可执行影响源。
–
WH proposes rules giving political appointees final approval on research grants33scientificamerican.com原文 ↗
scientificamerican.com
Scientific American 报道白宫拟议规则,将研究资助最终审批权交给政治任命官员。核心变化是 peer review 与行政裁量的边界可能被重画。对科研系统来说,这不只是流程新闻,而是会影响 grant selection、研究议题选择和机构风险判断的治理变化。
–
博客文章 · Blog Posts
10 项 · 博客文章
It's Not Just X. It's Y34mail.cyberneticforests.com原文 ↗
文章讨论 AI 训练栈里 post-training 的作用,反对把能力进步简单归因于“数据”。它的核心判断是 post-training 已经成为把数据转化为可用行为的工程层,包括偏好优化、RL、合成任务、评测循环和产品约束。值得看的是它把“数据叙事”和“训练后行为塑形”拆开,避免把模型能力来源讲成单变量故事。
–

The Speed of Prototyping in the Age of AI35darylcecile.net原文 ↗
darylcecile.net
这篇个人博客记录 AI 工具如何压缩原型开发时间。核心不是“写代码更快”这个表层结论,而是软件制作流程被重排:更多时间用于选择方向、剪枝范围、验证交互、整理 AI 生成代码和决定何时停手。它提供了一个现实视角:prototype 变便宜后,判断力和边界管理反而更重要。
–

Backpressure is all you need36lucasfcosta.com原文 ↗
lucasfcosta.com
文章解释 backpressure 在分布式系统和异步处理中的基础作用。它把队列、stream、worker pool、网络服务中的延迟、内存增长和丢弃策略串起来看:没有 backpressure,生产者会把消费者、队列或下游依赖压垮。值得看的是它把 backpressure 讲成系统控制面的必要机制,而不是性能调优小技巧。
–

Restartable Sequences37justine.lol原文 ↗
justine.lol
Justine Tunney 介绍 Linux restartable sequences。rseq 允许用户态定义可重启的 per-CPU 临界区,线程被抢占或迁移时由内核跳到 abort path,从而减少锁和系统调用开销。它值得看,因为 per-CPU counter、allocator 和极热路径数据结构常常需要这种“几乎不要同步成本”的机制。
–

The solution might be cancelling my AI subscription38thoughts.hmmz.org原文 ↗
thoughts.hmmz.org
文章反思 AI 工具带来的项目膨胀和任务漂移。作者的问题不是 AI 不够强,而是启动新方向、扩写范围和制造半成品变得太便宜,导致注意力被稀释。取消订阅在文中是一个约束机制:让项目重新回到有限时间、有限范围和明确完成标准。
–
May 2026 newsletter39simonwillison.net原文 ↗
工具使用其他垂直
Simon Willison 的月度通讯回顾 2026 年 5 月模型发布、工具使用和 Datasette 进展。它的价值在于把一整月的模型、工具和个人项目实践放进同一时间线,而不是只列发布链接。对跟踪 AI tooling 的读者来说,Simon 的月报通常更接近“实际用过后的技术日志”。
–

datasette 1.0a3240simonwillison.net原文 ↗
simonwillison.net
Datasette 1.0a32 发布说明修复 execute-write 和 base_url 相关问题。这个条目不大,但触及两个生产部署常见边界:写入执行路径和反向代理/子路径部署。对 Datasette 1.0 线来说,alpha 阶段这种小修复比功能发布更能反映稳定化进程。
–

pydantic-monty investigation41simonwillison.net原文 ↗
Simon Willison 记录对 Rust 实现 Python sandbox Monty 的调查。digest 指向的关键是 sandbox 的真实边界,而不是“Rust 写的所以安全”这类标签。它值得看作安全阅读样本:把 sandbox 的承诺拆成可执行行为、逃逸面、依赖假设和实际可用范围。
–

Sequoia Ascent 2026 summary42karpathy.bearblog.dev原文 ↗
karpathy.bearblog.dev
Andrej Karpathy 发布 Sequoia Ascent 2026 fireside chat 的 LLM 生成摘要和清理转录。这条的技术含义不在摘要内容本身,而在发布流程:转录、模型清理、人工筛选,再形成可读文本。它代表一种越来越常见的知识整理工作流,LLM 负责压缩和结构化,人负责判断取舍。
–

{kind=link}
The Sequence Radar #86943thesequence.substack.com原文 ↗
thesequence.substack.com
TheSequence 周报汇总上周 AI 模型、融资、平台和行业动态。它适合当横向情报源,而不是单篇深度技术材料。价值在于把模型发布、平台更新、融资和产品动向放在同一个周度节奏中,便于观察叙事和资本流向的同步变化。
–
GitHub 热门 · GitHub Trending
9 项 · GitHub 热门D4Vinci/Scrapling44github.com原文 ↗
github.com
Scrapling 是自适应网页抓取框架,从单请求到 full-scale crawl 都覆盖。它的 parser 会学习网站变化并自动 relocate elements,fetchers 声称可绕过 Cloudflare Turnstile,spider framework 支持并发、多 session、pause/resume、streaming stats 和 automatic proxy rotation。值得看的是它把现代抓取的三件难事:结构漂移、anti-bot、长任务 crawl,整合进一个 Python API。
–
nesquena/hermes-webui45github.com原文 ↗
Hermes WebUI 是 Hermes Agent 的浏览器端界面,Python + vanilla JS,无 build step,强调与 CLI 近 1:1 parity。界面是三栏:sessions/navigation、chat、workspace file browser,并把 model、profile、workspace controls 放在 composer footer。它背后的 Hermes 叙事包括 persistent memory、自托管 scheduled jobs、10+ messaging platforms、自改进 skills 和 provider-agnostic agent orchestration。
–
github/docs46github.com原文 ↗
github.com
github/docs 是 docs.github.com 的公开文档仓库。README 说明 GitHub 还有私有 docs-internal,二者频繁同步;公开仓库接受内容文件和部分 data 贡献,但不接受基础设施、workflow 和站点构建代码改动。它是商业文档开源协作的典型案例:内容开放协作,平台实现和内部流程保持边界。
–
supermemoryai/supermemory47github.com原文 ↗
Supermemory 是 AI 应用的 memory/context layer,提供 memory、RAG、user profiles、connectors 和 file processing 的统一 API。README 称其在 LongMemEval、LoCoMo、ConvoMem 三个 memory benchmark 上排名第一,并支持 Google Drive、Gmail、Notion、OneDrive、GitHub 等连接器。它值得看,因为它把 memory 与 RAG 区分开:memory 处理用户事实、矛盾、时态变化和自动遗忘,RAG 处理文档检索。
–
nicobailon/pi-subagents48github.com原文 ↗
pi-subagents 给 Pi 增加 async subagent delegation。父 session 可启动 focused child Pi session 做 review、scouting、implementation、parallel audits、background jobs,并把结果带回;内置 scout、researcher、planner、worker、reviewer、context-builder、oracle、delegate 等角色。工程看点在它的边界控制:child 默认不再注册 subagent tool,forked context 会过滤父级 orchestration artifacts,避免无限嵌套和上下文污染。
–
run-llama/liteparse49github.com原文 ↗
github.com
LiteParse 是本地开源文档解析工具,专注快速轻量 PDF parsing。它用 PDFium 做 spatial text parsing,输出带 bounding boxes 的 JSON/Text,可生成 screenshots;OCR 支持内置 Tesseract、HTTP OCR server 或自定义 API。Rust core 提供 Node.js、Python、Rust、WASM bindings 和统一 `lit` CLI,适合需要本地解析而不想引入云 LLM parser 的管线。
–
mattpocock/sandcastle50github.com原文 ↗
Sandcastle 是 TypeScript 库,用 `sandcastle.run()` 编排 sandboxed coding agents。它 provider-agnostic,内置 Docker、Podman、Vercel Firecracker microVM,也支持自定义 sandbox provider;运行后管理 branch strategy、agent 执行和 commits 合并。它的定位很明确:把多个 AFK coding agents、review pipeline 或 CI agent workflow 做成可编程 TypeScript API。
–
golemcloud/golem51github.com原文 ↗
Golem 是分布式运行 WebAssembly components 的服务集合,支持 Rust、TypeScript、Scala、MoonBit 构建 agents 和应用。仓库包含 worker executor、shard manager、registry、CLI、SDK、WIT、test components 等模块,并已有 300+ releases。它的技术主张是 durable execution:agent 和分布式应用不丢状态、不重复工作,开发者少建基础设施。
–
BloopAI/vibe-kanban52github.com原文 ↗
Vibe Kanban 是面向 Claude Code、Codex、Gemini CLI、Amp 等 coding agent 的任务规划和评审看板。它用 kanban issues 规划工作,为 agent 创建带 branch、terminal、dev server 的 workspace,并支持 diff review、inline comments、内置浏览器预览、PR 创建和合并。README 同时标注项目正在 sunsetting,这是评估采用风险时必须注意的状态信息。
–
引用来源 · References
52 条 · 引用- 1 DRIFT: Decoupled Rollouts and Importance-Weighted Fine-Tuning for Efficient Multi-Turn Optimization. arXiv:2605.31455https://arxiv.org/abs/2605.31455 ↩ 回到正文 · back to text
- 2 SCOPE: Self-Play via Co-Evolving Policies for Open-Ended Tasks. arXiv:2605.31433https://arxiv.org/abs/2605.31433 ↩ 回到正文 · back to text
- 3 LongDS-Bench: On the Failure of Long-Horizon Agentic Data Analysis. arXiv:2605.30434https://arxiv.org/abs/2605.30434 ↩ 回到正文 · back to text
- 4 Streambedhttps://github.com/viggy28/streambed ↩ 回到正文 · back to text
- 5 Striahttps://github.com/Reliary/stria ↩ 回到正文 · back to text
- 6 Emergent Languages in Populations of Language Model Agents: From Token Efficiency to Oversight Evasion. arXiv:2605.31170https://arxiv.org/abs/2605.31170 ↩ 回到正文 · back to text
- 7 Learning Agent-Compatible Context Management for Long-Horizon Tasks. arXiv:2605.30785https://arxiv.org/abs/2605.30785 ↩ 回到正文 · back to text
- 8 MAVEN: Improving Generalization in Agentic Tool Calling. arXiv:2605.30738https://arxiv.org/abs/2605.30738 ↩ 回到正文 · back to text
- 9 PReMISE: Policy Rubrics as Measurement Specifications for LLM Judges. arXiv:2605.30803https://arxiv.org/abs/2605.30803 ↩ 回到正文 · back to text
- 10 COMPASS: Cognitive MCTS-Guided Process Alignment for Safe Search Agents. arXiv:2605.30838https://arxiv.org/abs/2605.30838 ↩ 回到正文 · back to text
- 11 TraceGraph: Shared Decision Landscapes for Diagnosing and Improving Agent Trajectories. arXiv:2605.31308https://arxiv.org/abs/2605.31308 ↩ 回到正文 · back to text
- 12 From Prompt Injection to Persistent Control: Defending Agentic Harness Against Trojan Backdoors. arXiv:2605.31042https://arxiv.org/abs/2605.31042 ↩ 回到正文 · back to text
- 13 SAGE: A Novelty Gate for Efficient Memory Evolution in Agentic LLMs. arXiv:2605.30711https://arxiv.org/abs/2605.30711 ↩ 回到正文 · back to text
- 14 OpenSkillEval: Automatically Auditing the Open Skill Ecosystem for LLM Agents. arXiv:2605.23657https://arxiv.org/abs/2605.23657 ↩ 回到正文 · back to text
- 15 Interpretohttps://www.interpre.to ↩ 回到正文 · back to text
- 16 AgentThreatBenchhttps://github.com/OWASP/www-project-agent-memory-guard ↩ 回到正文 · back to text
- 17 Ministry of Everythinghttps://github.com/modulecollective/moe ↩ 回到正文 · back to text
- 18 Ralphyhttps://github.com/Mizerness/Ralphy ↩ 回到正文 · back to text
- 19 Atomic Editorhttps://kenforthewin.github.io/atomic-editor/ ↩ 回到正文 · back to text
- 20 xxUTFhttps://github.com/dzfrias/xxUTF ↩ 回到正文 · back to text
- 21 mcpguardhttps://github.com/GT-Projects256/mcpguard ↩ 回到正文 · back to text
- 22 Agentpackhttps://nexo.sh/posts/agentpack/ ↩ 回到正文 · back to text
- 23 Cordiumhttps://github.com/octelium/cordium ↩ 回到正文 · back to text
- 24 Monolithhttps://github.com/singlr-ai/monolith ↩ 回到正文 · back to text
- 25 Malaysia enforces ban on social media accounts for children younger than 16https://apnews.com/article/malaysia-social-media-ban-16-bfaa7b01163b61b5d53c4ecfa870d133 ↩ 回到正文 · back to text
- 26 Surface Laptop Ultra: Made for World Makershttps://blogs.windows.com/devices/2026/05/31/introducing-surface-laptop-ultra-made-for-world-makers/ ↩ 回到正文 · back to text
- 27 Nvidia RTX Sparkhttps://www.nvidia.com/en-us/products/rtx-spark/ ↩ 回到正文 · back to text
- 28 Welcome NVIDIA Cosmos 3: The First Open Omni-model for Physical AI Reasoning and Actionhttps://huggingface.co/blog/nvidia/cosmos-3-for-physical-ai ↩ 回到正文 · back to text
- 29 Meta launches Instagram, Facebook, and WhatsApp subscriptionshttps://techcrunch.com/2026/05/27/meta-officially-launches-instagram-facebook-and-whatsapp-subscriptions-with-more-to-come-including-ai-plans/ ↩ 回到正文 · back to text
- 30 The AV2 Video Standard Has Releasedhttps://av2.aomedia.org ↩ 回到正文 · back to text
- 31 Accenture to acquire Ooklahttps://newsroom.accenture.com/news/2026/accenture-to-acquire-ookla-to-strengthen-network-intelligence-and-experience-with-data-and-ai-for-enterprises ↩ 回到正文 · back to text
- 32 ChatGPT for Google Sheets exfiltrates workbookshttps://www.promptarmor.com/resources/gpt-for-google-sheets-data-exfiltration ↩ 回到正文 · back to text
- 33 WH proposes rules giving political appointees final approval on research grantshttps://www.scientificamerican.com/article/white-house-proposes-new-rules-giving-political-appointees-final-say-on-research-grants/ ↩ 回到正文 · back to text
- 34 It's Not Just X. It's Yhttps://mail.cyberneticforests.com/its-not-just-data-its-post-training/ ↩ 回到正文 · back to text
- 35 The Speed of Prototyping in the Age of AIhttps://darylcecile.net/notes/speed-of-prototyping-age-of-ai ↩ 回到正文 · back to text
- 36 Backpressure is all you needhttps://www.lucasfcosta.com/blog/backpressure-is-all-you-need ↩ 回到正文 · back to text
- 37 Restartable Sequenceshttps://justine.lol/rseq/ ↩ 回到正文 · back to text
- 38 The solution might be cancelling my AI subscriptionhttps://thoughts.hmmz.org/2026-05-31.html ↩ 回到正文 · back to text
- 39 May 2026 newsletterhttps://simonwillison.net/2026/Jun/1/may-newsletter/#atom-everything ↩ 回到正文 · back to text
- 40 datasette 1.0a32https://simonwillison.net/2026/May/31/datasette/#atom-everything ↩ 回到正文 · back to text
- 41 pydantic-monty investigationhttps://simonwillison.net/2026/May/22/monty-investigation/#atom-everything ↩ 回到正文 · back to text
- 42 Sequoia Ascent 2026 summaryhttps://karpathy.bearblog.dev/sequoia-ascent-2026/ ↩ 回到正文 · back to text
- 43 The Sequence Radar #869https://thesequence.substack.com/p/the-sequence-radar-869-last-week ↩ 回到正文 · back to text
- 44 D4Vinci/Scraplinghttps://github.com/D4Vinci/Scrapling ↩ 回到正文 · back to text
- 45 nesquena/hermes-webuihttps://github.com/nesquena/hermes-webui ↩ 回到正文 · back to text
- 46 github/docshttps://github.com/github/docs ↩ 回到正文 · back to text
- 47 supermemoryai/supermemoryhttps://github.com/supermemoryai/supermemory ↩ 回到正文 · back to text
- 48 nicobailon/pi-subagentshttps://github.com/nicobailon/pi-subagents ↩ 回到正文 · back to text
- 49 run-llama/liteparsehttps://github.com/run-llama/liteparse ↩ 回到正文 · back to text
- 50 mattpocock/sandcastlehttps://github.com/mattpocock/sandcastle ↩ 回到正文 · back to text
- 51 golemcloud/golemhttps://github.com/golemcloud/golem ↩ 回到正文 · back to text
- 52 BloopAI/vibe-kanbanhttps://github.com/BloopAI/vibe-kanban ↩ 回到正文 · back to text