
Agent libOS: A Library-OS-Inspired Runtime for Long-Running, Capability-Controlled LLM Agents 1 - 把长运行 agent 的状态、权限、恢复和审计放进 runtime,像给 agent 补一层应用态操作系统。
全文 ↓今日重点 · Today's Highlights

Proof-Carrying Agent Actions: Model-Agnostic Runtime Governance for Heterogeneous Agent Systems 2 - 用 action certificate 管住异构 agent 的高风险动作,治理边界从会话日志前移到执行前证明。
全文 ↓
SheetMog - OSS Excel alternative and headless SDK 3 - Rust/WASM spreadsheet engine 同时面向嵌入式 UI 和 headless agent API,是表格计算基础设施化的信号。
全文 ↓

Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories 5 - TELBench 与 DRIFT 把 deep-research agent 的错误定位到轨迹 span,而不是只给最终答案打分。
全文 ↓论文 · Papers
14 项 · 论文
Agentic Chain-of-Thought Steering for Efficient and Controllable LLM Reasoning6arxiv.org原文 ↗
ACTS 不是再给模型加一句“思考更短”的提示,而是在推理过程中插入一个控制器,让冻结的 reasoner 按预算、轨迹状态和任务难度动态改变思考策略。摘要称它把 steering 写成 MDP,并在多个 benchmark 上达到接近 full-thinking 的表现,同时减少推理 token;这使它更像 inference-time scheduler,而不是 prompt engineering。
–

Token Budgets: An Empirical Catalog of 63 LLM-Agent Budget-Overrun Incidents7arxiv.org原文 ↗
这篇把 agent token 超支整理成 63 起经验事件,关注的是预算如何在多轮工具调用、重试和长上下文中被隐性消耗掉。它的工程点在于把缓解示例落到 affine-typed Rust:预算被视为一次性资源来传递和消费,而不是事后统计的账单字段。
–
Benchmarks are Not Enough: RAMP for Runtime Assessing of Agentic Models in Production Systems8arxiv.org原文 ↗
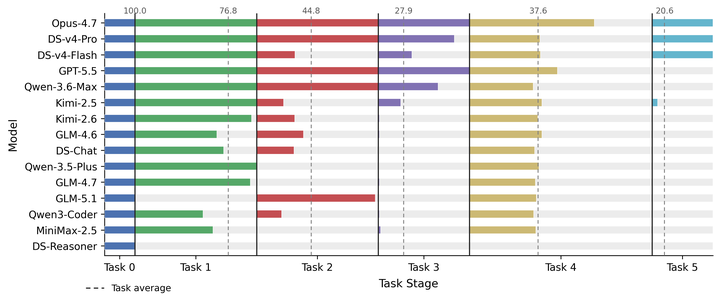
RAMP 的核心判断是静态 benchmark 不足以说明软件工程 agent 的生产能力,因此它用 YatCC 上的编译器构造任务、串行依赖和阶段恢复机制做 runtime assessment。作者评估 15 个主流模型,报告串行 workflow 完成率从首阶段 100% 降到末阶段 20%,没有模型完成完整 pipeline;这个结果把“能解单题”和“能维持长链路执行”区分开了。
–
Cascading Hallucination in Agentic RAG: The CHARM Framework for Detection and Mitigation9arxiv.org原文 ↗
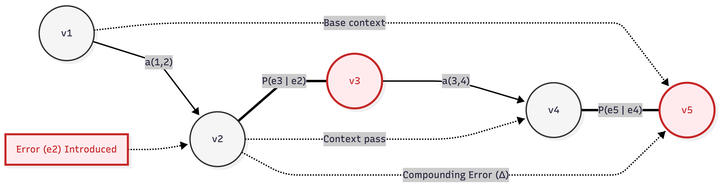
CHARM 把 agentic RAG 的错误传播命名为 cascading hallucination:早期检索或解释偏差会在后续步骤被放大,最后变成看似连贯的错误答案。摘要明确给出四类 cascade pattern,并把检测/缓解放在多步 pipeline 内部,这比只评估最终回答更接近 agentic RAG 的真实失败形态。
–
The Meta-Agent Challenge: Are Current Agents Capable of Autonomous Agent Development?10arxiv.org原文 ↗
Meta-Agent Challenge 测的是 frontier models 能否自主开发 agent 系统,而不是能否在单题上写代码。摘要将 MAC 定位为开放 benchmark,并把它作为评估 recursive self-improvement 的经验代理;这个设置把系统搭建、工具组合和自我迭代纳入同一个任务面。
–
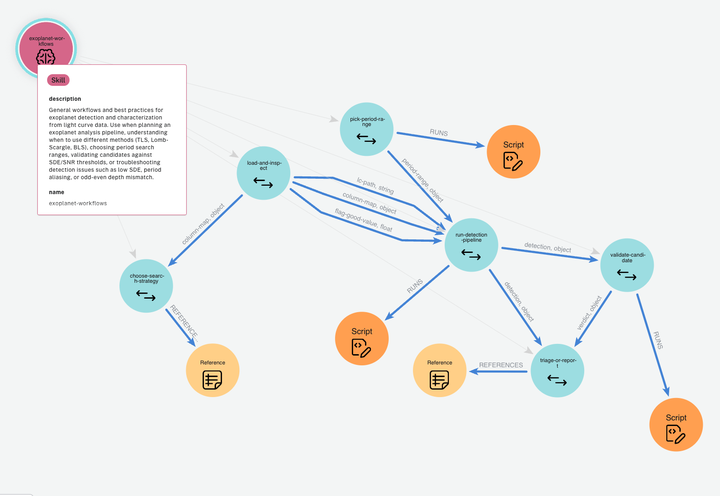

From Untrusted Input to Trusted Memory: A Systematic Study of Memory Poisoning Attacks in LLM Agents12arxiv.org原文 ↗
这篇把持久记忆当成 agent 的信任边界来研究:一次恶意写入可能在原始攻击交互结束后继续影响行为。摘要强调 single adversarial memory write 的长期作用,提示防线应覆盖写入、检索和使用记忆的全过程,而不是只过滤当前输入。
–

What If Prompt Injection Never Left? Exploring Cross-Session Stored Prompt Injection in Agentic Systems13arxiv.org原文 ↗
这项工作把 stored XSS 的思路搬到 agent 系统:一次注入成功后,恶意指令可能保存在记忆、文件或共享状态里,之后再被正常任务读取并执行。它关注 cross-session persistence,说明 prompt injection 的风险并不会随着当前聊天结束而消失。
–
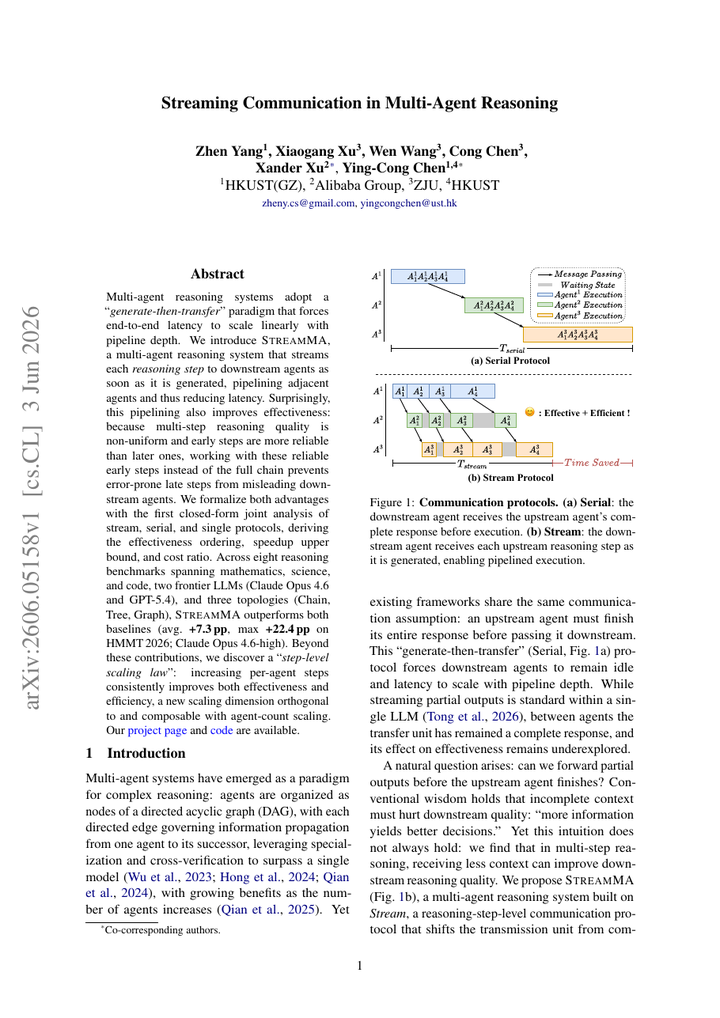
Streaming Communication in Multi-Agent Reasoning14arxiv.org原文 ↗
StreamMA 处理的是多 agent 协作里的同步瓶颈:一个 agent 生成到一半时,其他 agent 已经可以消费中间信息。摘要列出 8 个 reasoning benchmarks、Claude Opus 4.6 与 GPT-5.4 两个 frontier LLM,以及 Chain/Tree/Graph 三类拓扑;它的看点是把通信粒度从“整段消息”降到 streaming token/片段层。
–

AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?15arxiv.org原文 ↗
AutoLab 把 frontier model 放进 36 个现实长周期任务中,四个领域分别是系统优化、puzzle & challenge、模型开发和 CUDA kernel optimization。这样的设计把“会写第一版代码”与“能根据实验反馈持续推进”分离出来,适合作为自动研究/工程 agent 的耐力测试。
–

BraveGuard: From Open-World Threats to Safer Computer-Use Agents16arxiv.org原文 ↗
BraveGuard 的切入点是 computer-use agent 在真实多步执行中遇到的开放世界风险,而不是预先列好的安全标签。摘要指出,用 open-world threat discovery 和 realistic agent execution 做监督,可以提升 safety monitoring;这让它更接近浏览器/桌面 agent 的实际攻击面。
–
本期重点Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories5arxiv.org原文 ↗
这篇把 deep-research agent 的可靠性问题下钻到 span 级别:作者收集 2,790 条真实轨迹,转换成语义 span,再构建 1,000 实例 TELBench。DRIFT 以 claim 为中心追踪证据支持关系,报告在 span-level error localization 和 first-error accuracy 上最高提升 30 个百分点;它比只看最终答案更能解释研究轨迹何处开始偏航。
–
开源 / 项目 · Projects
13 项 · 开源 / 项目
Formally verified polygon intersection17github.com原文 ↗
github.com
这个项目做的是多边形相交算法的形式化验证,重点不在 UI 或性能包装,而在证明几何实现满足预期性质。README 还记录了 AI agent 辅助证明的过程,因此它同时是一个 verified geometry artifact 和一个“agent 帮助写证明”的案例。
–
本期重点SheetMog - OSS Excel alternative and headless SDK3github.com原文 ↗
工具使用数据·分析
SheetMog 做的是 Rust/WASM spreadsheet engine,目标是开源 Excel 替代和 headless SDK 的结合体。它把表格能力拆成可嵌入前端与程序化 API,对 agent 场景尤其有用,因为模型可以操作表格计算结构,而不必依赖屏幕坐标和 Excel 自动化。
–
OpenHack - OSS security scanner18github.com原文 ↗
github.com
OpenHack 是面向真实漏洞发现的开源安全 scanner,不满足于模式匹配,而是用开源 reasoning model 做代码语义理解、威胁建模、漏洞验证和 PoC 生成。项目页给出的对比是:在 17 个开源应用的 768 个已知漏洞上找到 265 个,finding accuracy 59%,并宣称比 frontier-model agents 便宜最高 40 倍。
–
FFmpeg WebCLI - Full FFmpeg in Browser, Offline PWA19github.com原文 ↗
github.com
FFmpeg WebCLI 把 FFmpeg 放进浏览器,通过 WASM/Web Worker 在本机处理媒体文件,并支持离线 PWA。这个项目的价值在隐私与部署形态:用户无需把视频上传到服务器,也不需要本机安装命令行 FFmpeg,就能完成转码、压缩和常见媒体处理。
–
Anthropic defending-code reference harness20github.com原文 ↗
这个仓库是 Anthropic 针对 AI 漏洞发现发布的 reference harness,核心作用是复现实验、统一运行目标和比较不同工具。它比单个“安全 agent”更底层:关注评测协议、样例环境和可重复性,便于判断工具是否真的发现漏洞而不是产生漂亮报告。
–
NeuroAnswer22github.com原文 ↗
NeuroAnswer 是给 Claude 使用的大规模脑图数据 MCP server,作用是把神经科学图谱查询封装成模型可调用工具。它的技术点在接口层:让 agent 通过 MCP 导航专业数据,而不是把整套脑图材料塞进普通上下文。
–
pico-10base-t-rs23github.com原文 ↗
github.com
pico-10base-t-rs 在 Raspberry Pi Pico 2 W 上用 Rust bit-bang 10BASE-T Ethernet,并把它接到 Wi-Fi router 场景里。它有明显的硬件 hack 味道:用 GPIO 和时序控制模拟以太网物理层,展示低成本 MCU 在网络协议边界上的可玩性。
–
AgentKitten24github.com原文 ↗
框架与脚手架其他垂直
AgentKitten 是面向 Apple 平台的 Swift agent 框架,设计目标是 provider-agnostic:同一套 agent 代码可接不同模型供应商。Swift Package Index 显示它有 7 个 library、1 个 macro、Apache 2.0 许可,并通过 Swift 并发相关的数据竞争检查;这使它更像原生应用侧 agent SDK,而不是 Web 后端框架。
–
openai-ads-mcp25github.com原文 ↗
openai-ads-mcp 把 ChatGPT Ads API 包成 MCP server,当前定位是只读查询账户、广告系列和投放数据。它属于“业务 API agent 化”的典型小工具:价值不在复杂推理,而在让 ChatGPT/Claude/Codex 类客户端以工具调用方式访问广告后台。
–
行业动态 · Industry News
10 项 · 行业动态VoidZero Is Joining Cloudflare28blog.cloudflare.com原文 ↗
blog.cloudflare.com
Cloudflare 将 VoidZero 团队纳入体系,覆盖 Vite、Vitest、Rolldown、Oxc 和 Vite+ 这组前端基础工具。Vite 官方声明强调治理、MIT 许可和 vendor-agnostic 方向不变;这笔交易的技术意义在于,构建工具链已成为云平台开发体验竞争的一部分,而不是单纯社区项目。
–
A Post-Quantum Future for Let's Encrypt29letsencrypt.org原文 ↗
letsencrypt.org
Let’s Encrypt 选择 Merkle Tree Certificates 作为后量子 Web PKI 路线,而不是简单把现有 X.509 签名替换为 ML-DSA。文章给出尺寸压力:ML-DSA-44 签名约 2,420 bytes,RSA-2048 是 256 bytes,ECDSA-P256 是 64 bytes;直接替换会把一次 TLS handshake 推到 10KB 以上。其计划是在 2026 年末提供 staging,2027 年达到 production-ready。
–
The ways we contain Claude across products30anthropic.com原文 ↗
Anthropic 这篇工程文把 agent 安全从“模型拒绝”拉回环境边界:gVisor 容器、devcontainer、VM、文件系统和 egress 控制才是限制 blast radius 的硬约束。文中给出两个有用数字:用户会批准约 93% 的 Claude Code 权限提示,而 Claude Code auto mode 在执行前能捕获约 83% 的 overeager behaviors;这解释了为什么人类确认框会迅速退化成疲劳点击。
–
When AI Builds Itself: Our progress toward recursive self-improvement31anthropic.com原文 ↗
Anthropic Institute 的报告讨论 AI 辅助自身开发的进展,也就是 recursive self-improvement 从抽象风险议题进入工程测量阶段。结合当天多篇 meta-agent 和 AutoLab 论文,这类报告的焦点已经从“模型能否写代码”转向“能否持续改进 agent 系统、评测和研发流程”。
–
Dreaming: Better memory for a more helpful ChatGPT32openai.com原文 ↗
OpenAI 的 Dreaming V3 把 ChatGPT 记忆从显式“请记住”扩展为后台综合历史对话的 memory synthesis。文章给出时间线:saved memories 在 2024 年 4 月上线,Dreaming V0 于 2025 年 4 月加入引用聊天历史,2026 版本强调 freshness、continuity 和 relevance;关键变化是记忆可被用户在 summary 页面审阅和修正。
–
Biodefense in the Intelligence Age33openai.com原文 ↗
openai.com
OpenAI 的 biodefense plan 把先进生物 AI 能力放在防御优先的框架下:帮助可信开发者构建疫情准备和生物安全能力,同时配套 safeguards、evidence 和 governance。文章连接到 2026 年 5 月的 Rosalind Biodefense,并把目标写成更早检测威胁、更快开发 countermeasures、更有协调性地响应危机。
–
How Endava is redesigning software delivery around AI agents34openai.com原文 ↗
openai.com
Endava 的案例重点不是单个开发者提效,而是把 ChatGPT Enterprise 和 Codex 放进 DavaFlow 生命周期。文章称这家 11,000 人公司把 AI 覆盖到会议准备、业务规划、产品发现、工程和部署,并扩展到 legal、finance、operations;这说明 agent adoption 的瓶颈会转移到需求、协调和治理流程。
–
How Wasmer used Codex to build a Node.js runtime for the edge35openai.com原文 ↗
openai.com
Wasmer 的案例给出清晰工程产物:Edge.js 让 Node.js workloads 在 WebAssembly sandbox 中运行,使 JavaScript apps、MCPs 和 agents 不依赖 Docker 部署到 edge。OpenAI 文中称开发速度提升 10x-20x,并把原本一年级别的 runtime 项目压缩到两周;更有意思的是 Codex 被用于低层调试,包括 console logs 和 LLD。
–
Pluto.jl 1.0 release36discourse.julialang.org原文 ↗
discourse.julialang.org
Pluto.jl 1.0 标志 Julia reactive notebook 进入稳定阶段。Pluto 的独特处在于 notebook 保存为纯 Julia 文件,并根据 cell 依赖自动重算;对科学计算和教学来说,它减少了 Jupyter 式隐藏执行顺序带来的状态漂移。
–
Gemma 4 12B37x.com原文 ↗
x.com
Gemma 4 12B 的看点是 encoder-free multimodal:文本、图像、音频、视频进入统一 decoder-only 路径,而不是外接独立 encoder。公开资料称它是 12B 参数、256K context、Apache 2.0 open weights,并可在约 16GB laptop 上运行;这让本地多模态 assistant 的硬件门槛继续下降。
–
博客文章 · Blog Posts
8 项 · 博客文章
They’re made out of weights38maxleiter.com原文 ↗
maxleiter.com
Max Leiter 这篇短文的价值在于反人格化:模型行为最终来自 weights、训练数据和推理计算,而不是一个稳定内在主体。它适合作为 AI 讨论中的概念校准,提醒读者不要把模型的流畅语言直接解释成意图、信念或理解。
–

I built a vulnerable app and spent $1,500 seeing if LLMs could hack it39kasra.blog原文 ↗
kasra.blog
Kasra Rahjerdi 的实验把“LLM 会不会 hack”落到一个自建脆弱应用和真实 API 成本上。文章写到原计划每个目标模型做 10 次运行,但最终花到 1,500 美元不得不停下;一个关键背景是作者账户已获安全研究批准,所以 GPT 没有因为安全策略而拒绝参与测试。
–

Reviewing code requires reading40hauleth.dev原文 ↗
hauleth.dev
Hauleth 这篇把代码审查重新定义为阅读任务,而不是“看 diff 找瑕疵”的仪式。它强调 reviewer 必须理解上下文、执行路径和作者意图;在 agent 生成代码变多后,这种观点更有现实意义,因为审查对象可能看起来整洁但缺少设计语境。
–

Designing the hf CLI as an agent-optimized way to work with the Hub41huggingface.co原文 ↗
Hugging Face 把 hf CLI 明确设计成 agent 可用接口,而不是只服务人类终端用户。文档提到 Claude Code、OpenAI Codex、Open Code 可通过 `hf` 操作 Hub,并提供 `agent`、`json`、`quiet` 等输出模式;这类 CLI 细节会直接影响 agent 调用工具时的可解析性和失败恢复。
–

Nemotron 3.5 Content Safety42huggingface.co原文 ↗
huggingface.co
Nemotron 3.5 Content Safety 是 NVIDIA 面向内容审核的专用小模型,NIM model card 显示其以 Google Gemma-3-4B-it 为 base,并在多模态、多语言安全数据上 fine-tune。相比通用大模型做安全判断,专用 guard model 的优势在延迟、成本和可定制 policy。
–

EVA-Bench Data 2.043huggingface.co原文 ↗
EVA-Bench Data 2.0 面向 voice agents,包含 3 个企业领域、121 个工具和 213 个场景。相关论文摘要给出一个强信号:评估的 12 个系统中,没有系统同时在 EVA-A pass@1 和 EVA-X pass@1 超过 0.5,且 median pass@k - pass^k gap 为 0.44;这说明语音 agent 的峰值能力和可靠能力差距很大。
–

The Sequence Opinion #872: The Cake Is a Battlefield44thesequence.substack.com原文 ↗
thesequence.substack.com
TheSequence 这篇把 AI stack 描述成多层战场:能源、芯片、基础设施、模型和应用都在争夺利润池与控制权。它的视角不是模型排行榜,而是产业结构;当训练/推理成本、云绑定和分发渠道一起变化时,技术优势会被上游资源和下游入口重新定价。
–
{kind=link}
not much happened today45news.smol.ai原文 ↗
news.smol.ai
smol.ai 的“not much happened today”是社区动态聚合,而不是单一新闻报道。它的价值在于宽口径扫描模型发布、agent 基础设施、benchmark、开源仓库和社交讨论;这类日报常把正式公告之外的生态信号提前暴露出来。
–
GitHub 热门 · GitHub Trending
12 项 · GitHub 热门aquasecurity/trivy46github.com原文 ↗
github.com
Trivy 是云原生安全扫描器,覆盖 container image、filesystem、Kubernetes、代码仓库、cloud resources、secrets、misconfigurations 和 SBOM。它的广泛使用来自“一个 CLI 覆盖多类目标”的工程取舍,适合 CI/CD 中做基础安全门禁。
–
NousResearch/hermes-agent47github.com原文 ↗
Hermes Agent 是 Nous Research 的 self-improving agent,围绕持久记忆、自动生成 skills 和会话检索构建。README 索引显示它支持 Nous Portal、OpenRouter 200+ models、NVIDIA NIM、OpenAI 和自定义 endpoint,并可从 OpenClaw 导入设置、记忆、skills 与 API keys;这是 agent runtime 正在走向“可迁移个人环境”的例子。
–
opendataloader-project/opendataloader-pdf48github.com原文 ↗
github.com
OpenDataLoader-PDF 面向 AI 数据抽取,把 PDF 转成 Markdown、带 bounding boxes 的 JSON 和 HTML。README 索引声称 benchmark overall 0.907;它的实用点在于保留布局与结构信息,减少 RAG 或信息抽取时“PDF 变纯文本”造成的证据错位。
–
odoo/odoo49github.com原文 ↗
github.com
Odoo 是模块化开源业务应用套件,覆盖 CRM、eCommerce、accounting、inventory、point of sale、project management、HR 等模块。它的技术看点不是新颖框架,而是把大量企业流程放到同一可扩展平台;对 agent 来说,这类系统也是高价值工具调用目标。
–
NVIDIA-NeMo/Gym50github.com原文 ↗
NeMo Gym 用“environment”统一评估和训练 agent:一个环境包含 dataset、agent harness、verifier 和 per-task state。README 强调可扩展到数千并发环境,并能在评估、agent optimization 和训练之间切换;它对应的是 agent benchmark 从静态问答向可执行环境迁移。
–
datawhalechina/hello-agents51github.com原文 ↗
Hello-Agents 是 Datawhale 的中文 agent 教程,定位为从原理到实践的系统学习材料。它面向“真正的 AI Native Agent”构建,而不是只讲 prompt;在中文生态中,这类开源教程能降低 agent 架构、工具调用和多智能体实践的入门成本。
–
OpenMOSS/MOSS-TTS52github.com原文 ↗
github.com
MOSS-TTS 是 OpenMOSS 的开源 speech/sound generation family,覆盖 long-form speech、多 speaker dialogue、voice design、environmental sound effects 和 streaming TTS。相关 MOSS-TTSD 摘要提到最长 60 分钟 single-pass dialogue synthesis、最多 5 个 speaker 和短参考音频 zero-shot voice cloning;这把 TTS 从短句朗读扩展到内容生产级对话生成。
–
OpenBMB/VoxCPM53github.com原文 ↗
github.com
VoxCPM 的路线是 tokenizer-free TTS:通过端到端扩散自回归架构直接生成连续语音表征,绕过离散音频 token。项目页强调 zero-shot voice cloning 和 voice design;VoxCPM2 资料称其为 2B 参数、训练于 2M+ 小时多语言音频的模型,面向多语言语音生成。
–
anthropics/claude-code54github.com原文 ↗
Claude Code 是 Anthropic 的终端内 agentic coding tool:它读取代码库、编辑文件、执行命令,并通过自然语言处理 git workflow。与 autocomplete 不同,它是完整开发任务执行器,因此权限、沙箱、日志和 review 流程都成了产品核心,而不只是模型能力展示。
–
aaif-goose/goose55github.com原文 ↗
Goose 是 AAIF 下的开源 AI agent,提供 Desktop、CLI 和 API 形态。官方文档称它可自动化软件开发任务,并通过工具/扩展连接本地工作流;在 agent 标准化背景下,Goose 的意义还包括把 Block 原项目迁入 Linux Foundation 生态。
–
graykode/abtop56github.com原文 ↗
abtop 把 btop 风格监控带到 AI coding agents:它展示 token usage、context window utilization、rate limits、child processes、open ports 和 git stats。随着 agent 长时间运行,监控对象从 CPU/内存扩展到上下文窗口、成本、子进程和端口占用,这是很实际的运维层补齐。
–
BoundaryML/baml57github.com原文 ↗
BAML 用 schema-first 的方式定义 AI-powered functions:开发者写类型、prompt 和输出结构,框架把 schema 注入 prompt 并帮助解析结果。它解决的是生产 AI workflow 中的结构化输出可靠性,而不是再造一个 agent;在多步骤 agent 里,稳定的 typed boundary 往往比更长提示词更关键。
–
引用来源 · References
57 条 · 引用- 1 Agent libOS: A Library-OS-Inspired Runtime for Long-Running, Capability-Controlled LLM Agents. arXiv:2606.03895https://arxiv.org/abs/2606.03895 ↩ 回到正文 · back to text
- 2 Proof-Carrying Agent Actions: Model-Agnostic Runtime Governance for Heterogeneous Agent Systems. arXiv:2606.04104https://arxiv.org/abs/2606.04104 ↩ 回到正文 · back to text
- 3 SheetMog - OSS Excel alternative and headless SDKhttps://github.com/fundamental-research-labs/mog ↩ 回到正文 · back to text
- 4 KVarNhttps://github.com/huawei-csl/KVarN ↩ 回到正文 · back to text
- 5 Where Do Deep-Research Agents Go Wrong? Span-Level Error Localization in Agent Trajectories. arXiv:2606.02060https://arxiv.org/abs/2606.02060 ↩ 回到正文 · back to text
- 6 Agentic Chain-of-Thought Steering for Efficient and Controllable LLM Reasoning. arXiv:2606.03965https://arxiv.org/abs/2606.03965 ↩ 回到正文 · back to text
- 7 Token Budgets: An Empirical Catalog of 63 LLM-Agent Budget-Overrun Incidents. arXiv:2606.04056https://arxiv.org/abs/2606.04056 ↩ 回到正文 · back to text
- 8 Benchmarks are Not Enough: RAMP for Runtime Assessing of Agentic Models in Production Systems. arXiv:2605.27492https://arxiv.org/abs/2605.27492 ↩ 回到正文 · back to text
- 9 Cascading Hallucination in Agentic RAG: The CHARM Framework for Detection and Mitigation. arXiv:2606.04435https://arxiv.org/abs/2606.04435 ↩ 回到正文 · back to text
- 10 The Meta-Agent Challenge: Are Current Agents Capable of Autonomous Agent Development?. arXiv:2606.04455https://arxiv.org/abs/2606.04455 ↩ 回到正文 · back to text
- 11 AIP: A Graph Representation for Learning and Governing Agent Skills. arXiv:2606.04781https://arxiv.org/abs/2606.04781 ↩ 回到正文 · back to text
- 12 From Untrusted Input to Trusted Memory: A Systematic Study of Memory Poisoning Attacks in LLM Agents. arXiv:2606.04329https://arxiv.org/abs/2606.04329 ↩ 回到正文 · back to text
- 13 What If Prompt Injection Never Left? Exploring Cross-Session Stored Prompt Injection in Agentic Systems. arXiv:2606.04425https://arxiv.org/abs/2606.04425 ↩ 回到正文 · back to text
- 14 Streaming Communication in Multi-Agent Reasoning. arXiv:2606.05158https://arxiv.org/abs/2606.05158 ↩ 回到正文 · back to text
- 15 AutoLab: Can Frontier Models Solve Long-Horizon Auto Research and Engineering Tasks?. arXiv:2606.05080https://arxiv.org/abs/2606.05080 ↩ 回到正文 · back to text
- 16 BraveGuard: From Open-World Threats to Safer Computer-Use Agents. arXiv:2606.01166https://arxiv.org/abs/2606.01166 ↩ 回到正文 · back to text
- 17 Formally verified polygon intersectionhttps://github.com/schildep/verified-polygon-intersection ↩ 回到正文 · back to text
- 18 OpenHack - OSS security scannerhttps://github.com/openhackai/openhack ↩ 回到正文 · back to text
- 19 FFmpeg WebCLI - Full FFmpeg in Browser, Offline PWAhttps://github.com/tejaswigowda/ffmpeg-webCLI ↩ 回到正文 · back to text
- 20 Anthropic defending-code reference harnesshttps://github.com/anthropics/defending-code-reference-harness ↩ 回到正文 · back to text
- 21 Boxes.devhttps://boxes.dev ↩ 回到正文 · back to text
- 22 NeuroAnswerhttps://github.com/cjmielke/NeuroAnswer ↩ 回到正文 · back to text
- 23 pico-10base-t-rshttps://github.com/mattdeeds/pico-10base-t-rs ↩ 回到正文 · back to text
- 24 AgentKittenhttps://github.com/fbeeper/agentkitten ↩ 回到正文 · back to text
- 25 openai-ads-mcphttps://github.com/HYPD-AI/openai-ads-mcp ↩ 回到正文 · back to text
- 26 Lookspanhttps://github.com/JoniMartin27/lookspan ↩ 回到正文 · back to text
- 27 Mnemohttps://github.com/zaydmulani09/mnemo ↩ 回到正文 · back to text
- 28 VoidZero Is Joining Cloudflarehttps://blog.cloudflare.com/voidzero-joins-cloudflare/ ↩ 回到正文 · back to text
- 29 A Post-Quantum Future for Let's Encrypthttps://letsencrypt.org/2026/06/03/pq-certs ↩ 回到正文 · back to text
- 30 The ways we contain Claude across productshttps://www.anthropic.com/engineering/how-we-contain-claude ↩ 回到正文 · back to text
- 31 When AI Builds Itself: Our progress toward recursive self-improvementhttps://www.anthropic.com/institute/recursive-self-improvement ↩ 回到正文 · back to text
- 32 Dreaming: Better memory for a more helpful ChatGPThttps://openai.com/index/chatgpt-memory-dreaming ↩ 回到正文 · back to text
- 33 Biodefense in the Intelligence Agehttps://openai.com/index/biodefense-in-the-intelligence-age ↩ 回到正文 · back to text
- 34 How Endava is redesigning software delivery around AI agentshttps://openai.com/index/endava-frontiers ↩ 回到正文 · back to text
- 35 How Wasmer used Codex to build a Node.js runtime for the edgehttps://openai.com/index/wasmer ↩ 回到正文 · back to text
- 36 Pluto.jl 1.0 releasehttps://discourse.julialang.org/t/pluto-1-0-release/137296 ↩ 回到正文 · back to text
- 37 Gemma 4 12Bhttps://x.com/JeffDean/status/2062353800657342903 ↩ 回到正文 · back to text
- 38 They’re made out of weightshttps://maxleiter.com/blog/weights ↩ 回到正文 · back to text
- 39 I built a vulnerable app and spent $1,500 seeing if LLMs could hack ithttps://kasra.blog/blog/i-spent-1500-seeing-if-llms-could-hack-my-app/ ↩ 回到正文 · back to text
- 40 Reviewing code requires readinghttps://hauleth.dev/post/review-requires-reading/ ↩ 回到正文 · back to text
- 41 Designing the hf CLI as an agent-optimized way to work with the Hubhttps://huggingface.co/blog/hf-cli-for-agents ↩ 回到正文 · back to text
- 42 Nemotron 3.5 Content Safetyhttps://huggingface.co/blog/nvidia/nemotron-3-5-content-safety ↩ 回到正文 · back to text
- 43 EVA-Bench Data 2.0https://huggingface.co/blog/ServiceNow-AI/eva-bench-data ↩ 回到正文 · back to text
- 44 The Sequence Opinion #872: The Cake Is a Battlefieldhttps://thesequence.substack.com/p/the-sequence-opinion-872-the-cake ↩ 回到正文 · back to text
- 45 not much happened todayhttps://news.smol.ai/issues/26-06-03-not-much/ ↩ 回到正文 · back to text
- 46 aquasecurity/trivyhttps://github.com/aquasecurity/trivy ↩ 回到正文 · back to text
- 47 NousResearch/hermes-agenthttps://github.com/NousResearch/hermes-agent ↩ 回到正文 · back to text
- 48 opendataloader-project/opendataloader-pdfhttps://github.com/opendataloader-project/opendataloader-pdf ↩ 回到正文 · back to text
- 49 odoo/odoohttps://github.com/odoo/odoo ↩ 回到正文 · back to text
- 50 NVIDIA-NeMo/Gymhttps://github.com/NVIDIA-NeMo/Gym ↩ 回到正文 · back to text
- 51 datawhalechina/hello-agentshttps://github.com/datawhalechina/hello-agents ↩ 回到正文 · back to text
- 52 OpenMOSS/MOSS-TTShttps://github.com/OpenMOSS/MOSS-TTS ↩ 回到正文 · back to text
- 53 OpenBMB/VoxCPMhttps://github.com/OpenBMB/VoxCPM ↩ 回到正文 · back to text
- 54 anthropics/claude-codehttps://github.com/anthropics/claude-code ↩ 回到正文 · back to text
- 55 aaif-goose/goosehttps://github.com/aaif-goose/goose ↩ 回到正文 · back to text
- 56 graykode/abtophttps://github.com/graykode/abtop ↩ 回到正文 · back to text
- 57 BoundaryML/bamlhttps://github.com/BoundaryML/baml ↩ 回到正文 · back to text